Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)
week4
streaming data format
下面讲 data lakes

schema-on-read: 从数据源读取raw data 直接放到 data lake 里,然后再读到model里
schema-on-write: 传统模式,把raw data 经过处理后放到data warehouse里,此时已经是结构化的数据,然后直接load 出来

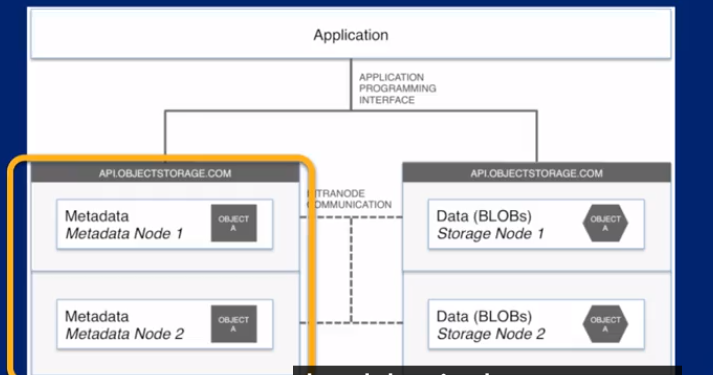
data lake summary

week5 - big data management
针对大数据,传统DBMS 需要提高的地方

some solutiion

from DBMS to BDMS
BDMS 应该具有的特征



BASE 就是基于CAP理论的

一些常用的BDMS及其优缺点
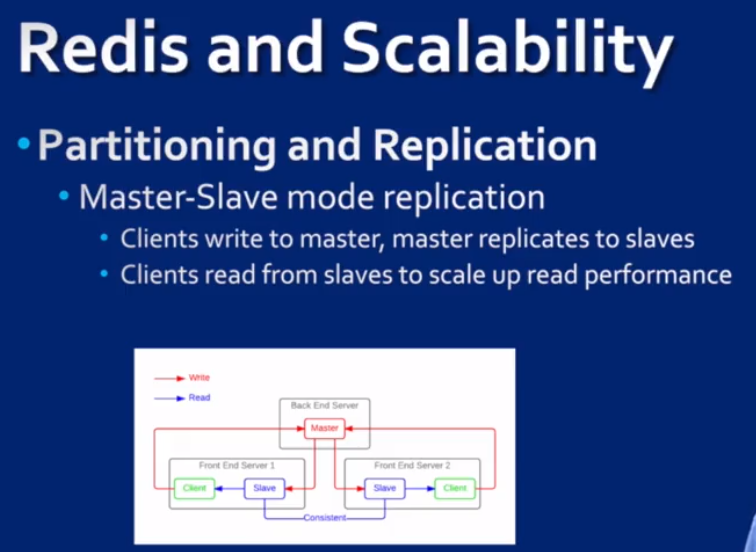
Redis: an enhanced key-value store




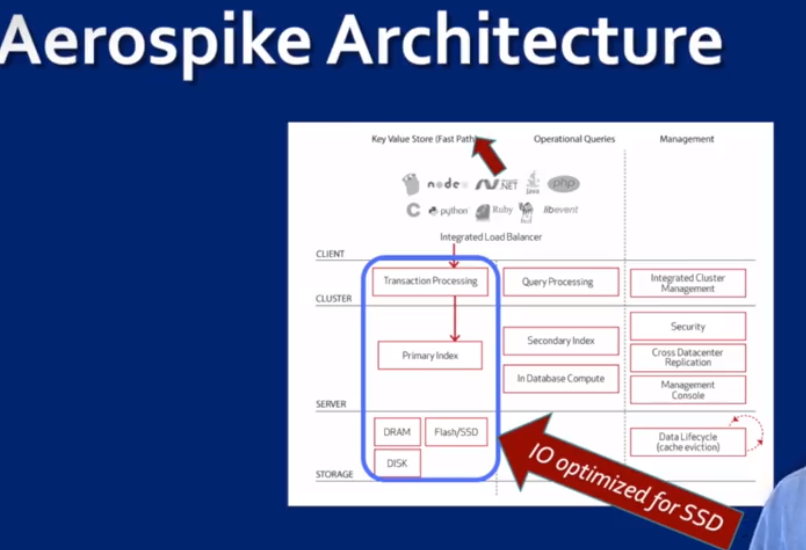
Aerospike: a new generation KV store
这是一个分布式NoSQL database + KV store. 是强一致性的



AsterixDB: a DBMS for semistructured data. 大家都知道的mongodb 以json 格式存储j数据, 这个Asterix 和 mongodb 类似. 它提供ACID保证.

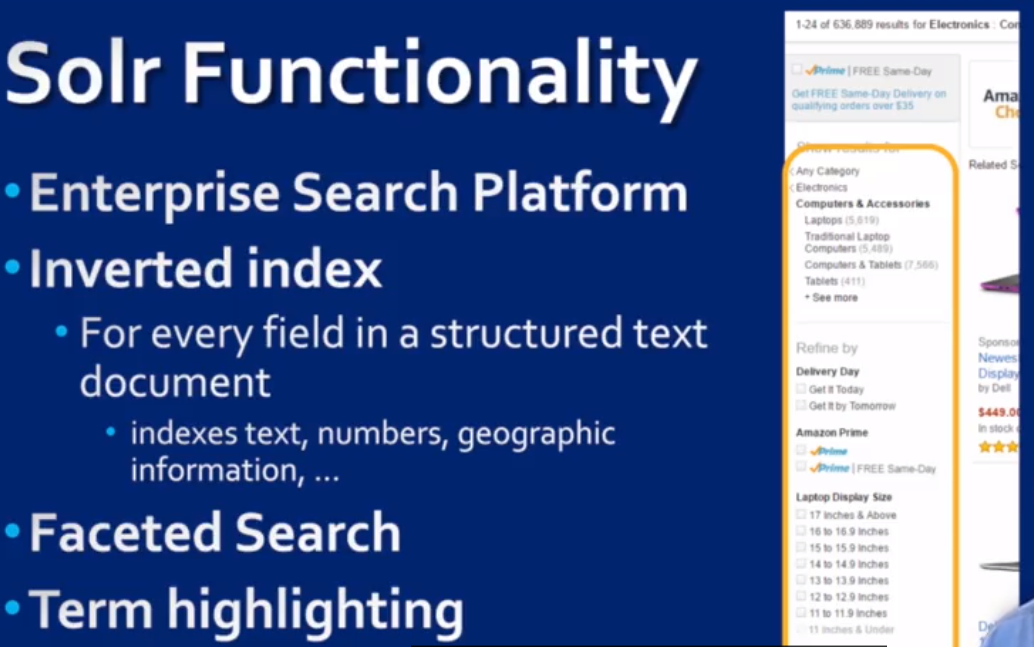
Solr : Text data searching. 基于Lucene的
应该是一种search engine, 不知道和 ES 什么区别.

反向索引,至少要包含 doc id list, 也可以包含更多信息

除了full text search, 还有下面的功能
Vertica:a columnar DBMS

Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)的更多相关文章
- Coursera, Big Data 2, Modeling and Management Systems (week 1/2/3)
Introduction to data management 整个coures 2 是讲data management and storage 的,主要内容就是分布式文件系统,HDFS, Redis ...
- Coursera, Big Data 3, Integration and Processing (week 4)
Week 4 Big Data Precessing Pipeline 上图可以generalize 成下图,也就是Big data pipeline some high level processi ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data KNime - GUI based Spark MLlib - inside Spark CRISP-DM Week 2, ...
- Coursera, Big Data 3, Integration and Processing (week 5)
Week 5, Big Data Analytics using Spark Programing in Spark Spark Core: Programming in Spark us ...
- Coursera, Big Data 3, Integration and Processing (week 1/2/3)
This is the 3rd course in big data specification courses. Data model reivew 1, data model 的特点: Struc ...
- Coursera, Big Data 1, Introduction (week 3)
什么是分布式文件系统?为什么需要分布式文件系统? 如果文件系统可以管理用网络连接的很多个存储单元,叫分布式文件系统. 分布式文件系统提供了数据可扩展性,容错性,高并发. 这些是传统文件系统不具有的. ...
- Coursera, Big Data 1, Introduction (week 1/2)
Status: week 2 done. Week 1, 主要讲了大数据的的来源 - 机器产生的数据,人产生的数据(比如社交软件上的update, 一般是unstructed data), 组织产生的 ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
- [label][Node.js] Three content management systems base on Node.js
1. Keystonejs http://keystonejs.com/ 2. Apostrophe http://apostrophenow.org/
随机推荐
- day12-内置模块学习(三)
我的博客呀,从以前的预习变成了复习了,复习的东西还没有写完,哎 今日目录 1.序列化模块 2.加密模块 3.包的使用 4.random模块 5.shutil模块 开始今日份总结 1.序列化模块 在学习 ...
- i春秋 百度杯”CTF比赛 十月场 login
出现敏感的信息,然后进行登录 登录成功发现奇怪的show 然后把show放到发包里面试一下 出现了源码,审计代码开始 出flag的条件要user 等于春秋 然后进行login来源于反序列化后的logi ...
- Vultr CentOS 7 安装 Docker
前言 最近在梳理公司的架构,想用 VPS 先做一些测试,然后就开始踩坑了!我用 Vultr 新买了个 VPS. 安装的 CentOS 版本: [root@dbn-seattle ~]# cat /et ...
- Spring-data-redis操作redis知识总结
什么是spring-data-redis spring-data-redis是spring-data模块的一部分,专门用来支持在spring管理项目对redis的操作,使用java操作redis最常用 ...
- stm32之不定长接收
使用STM32CUBE_MAX配置工程,可以简化编程工作量,但是这样我们会遇到一些麻烦,比如利用串口接收不知道长度的数据的时候,我们可能会无从下手,前段时间看到他人程序中的串口不定长接收,此次特意总结 ...
- TypeError: 'Item' object has no attribute '__getitem__'
Error Msg: Traceback (most recent call last): File "start.py", line 8, in <module> E ...
- HTTP常见错误返回状态代码
当⽤用户试图通过HTTP或FTP协议访问⼀一台运⾏行行主机上的内容时,Web服务器器返回⼀一个表示该请求的状态的数字代码.该状态代码记录在服务器器⽇日志中,同时也可能在Web 浏览器器或 FTP客户端 ...
- c++ fmt 库安装和使用示例
安装: 1 git clone https://github.com/fmtlib/fmt.git 2. cmake . 3. make && make install #incl ...
- 利用CocoaHttpServer搭建手机本地服务器
原理 使用CocoaHTTPServer框架,在iOS端建立一个本地服务器,只要电脑和手机连入同一热点或者说网络,就可以实现通过电脑浏览器访问iOS服务器的页面,利用POST实现文件的上传. 实现 1 ...
- day05(数字类型,字符串类型,列表类型)
一,复习: 1.顺序结构.分支结构.循环结构 2.if分支结构 if 条件: 代码块 elif 条件: 代码块 else: 代码块 # 可以被if转换为False:0 | '' | None | [] ...