python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识
一、python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, 一般都是操作时没有进行转码操作.而转码则需要decode(解码)和encode(编码)方法.
如:
str1.decode(‘gbk’), 表示将gbk编码的字符串‘str1’转换成unicode编码.
str2.encode(‘gbk’), 表示将unicode编码的字符串‘str2’转换gbk编码.
二、写入数据的时候报错程序直接停止,这就不得不重视“Python UnicodeEncodeError: 'gbk' codec can't encode character ”解决方法
将网络数据流写入文件时时,我们会遇到几个编码:
1: #encoding='XXX' 这里(也就是python文件第一行的内容)的编码是指该python脚本文件本身的编码,无关紧要。只要XXX和文件本身的编码相同就行了。 比如notepad++ "格式"菜单里面里可以设置各种编码,这时需要保证该菜单里设置的编码和encoding XXX相同就行了,不同的话会报错
2:网络数据流的编码 比如获取网页,那么网络数据流的编码就是网页的编码。需要使用decode解码成unicode编码。
3:目标文件的编码 要将网络数据流的编码写入到新文件,那么我么需要指定新文件的编码。在windows下面,新文件的默认编码是gbk,这样的话,python解释器会用gbk编码去解析我们的网络数据流txt,然而txt此时已经是decode过的unicode编码,这样的话就会导致解析不了,出现上述问题。 解决的办法就是,改变目标文件的编码:
f = open("out.html","w",encoding='utf-8')
三、pycharm缩进
1、pycharm使多行代码同时缩进、左移
鼠标选中多行代码后,按下Tab键,一次缩进四个字符
2、pycharm使多行代码同时左移
鼠标选中多行代码后,同时按住shift+Tab键,一次左移四个字符
四、time.sleep(t)
参数:t -- 推迟执行的秒数。
五、selenium 元素可以定位到,但是无法点击问题
描述:页面元素可以定位到,但是无法点击click。元素可能被一个透明div覆盖了
解决方案:
1.在执行click之前多休眠几秒
2.确认自己的元素是否定位正确,是否有id,name,class相同的元素,加下划线的是遮挡的div确定它的位置判断他的z_index是否大于你要点击元素的z_index
3.用Enter键代替click
4、将页面拖拽到要点击的元素位置,例如百度文库点击继续阅读展示全部内容(代码如下)
from selenium import webdriver
from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome('D:/chromedriver.exe')
driver.get("https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html")
page = driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/span/span[2]")
driver.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去
driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
六、爬取百度文库连接:https://wenku.baidu.com/view/df34290a763231126edb11f9.html
原本我就没有想着要去用自动化工具去爬取,本来想着取用requests模拟请求,顶多就是麻烦一下弄弄js,但是我一看百度文库它的请求头

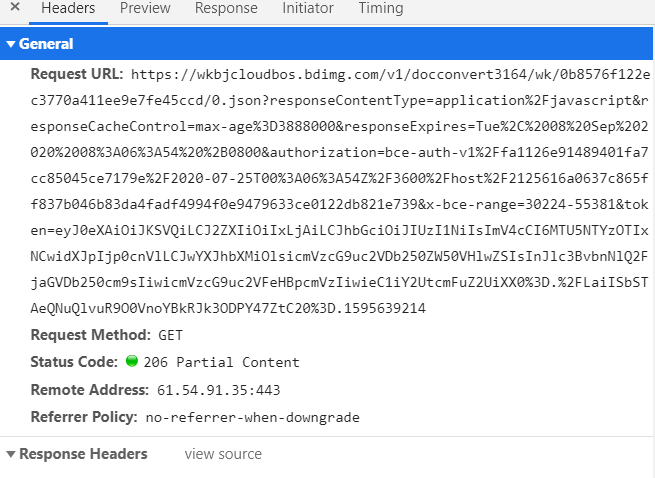
找这个文件找了半天,主要是它的文字不是连续的,我刚开始大致一看都没有找到。我还以为怎么了(翻车现场)。。。弄了半天可以确定0.png?这样类型的传递的是文库的照片,0.json传递的是文库的文字
但是这个请求头的url太长了,,突然就不想用requests模拟请求了
那就用selenium自动化工具+bs4解析页面,如果没有安装python的selenium库和selenium对应的浏览器驱动可以看一下:安装python的selenium库和驱动
接下来我们把思路和代码说一下
1、首先导入一下需要用到的模块
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
2、因为这个页面是动态的,我们的selenium检测到浏览器框架之后就会返回源码,但是它不会去检测这个页面的动态加载部分是否加载出来,所以我们需要要求它去检测一下

这两个东西就是表示的是百度文库中文库是第几页,上图表示的是百度文库的第二页的div元素,第三页如下

这样我就可以确定,这个肯定可以作为检测条件
num = input('输入总页数:')
st = "pageNo-"
st_nums = st+str(num) #先构建一下最后一页的属性值
3、使用selenium模拟浏览器,并打开指定网址
browser = webdriver.Chrome("D:\python-senium\chromedriver.exe")#里面传的参数是你selenium驱动所在位置
browser.get('https://wenku.baidu.com/view/df34290a763231126edb11f9.html') #发送请求
4、我们使用selenium中的显示等待,初始化最长等待时间为10s。并等待我们要点击“继续阅读”出现,然后将浏览器页面移动到这里
wait = WebDriverWait(browser,10)
time.sleep(5)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#html-reader-go-more > div.continue-to-read > div.banner-more-btn > span')))#等待条件:找到文库中“继续阅读”字样,并等待其出现
page = browser.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/span") #找到页面中“继续阅读”所在位置
#js = "document.getElementsByClassName('banner-more-btn').style.visibility='hidden'"
#browser.execute_script(js) #这个js代码是我原来以为是“继续阅读”被一个空的div包裹所以不能点击,然后我尝试把这个div掩盖掉,结果js代码运行失败。。。
browser.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素“继续阅读”去
5、等待“继续阅读”可以点击就点击它,然后等待文库中最后一页也加载出来就返回页面源码
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#html-reader-go-more > div.continue-to-read > div.banner-more-btn > span'))).click()
wait.until(EC.presence_of_element_located((By.ID,st_nums))) #等待文库中最后一页也加载出来
html = browser.page_source
6、我们发现这些文字都被一个class属性值为“ie-fix”所包裹,那我们就把它所包裹的p标签都拿出来

its_p = soup.select(".ie-fix p")
然后对这个列表进行遍历,并输出其中的文本,并写入文件ab.txt中
soup = BeautifulSoup(html,"html.parser") #使用python内置解析html库
def get_context():
try:
its_p = soup.select(".ie-fix p")
for it_p in its_p:
print(it_p.text,end='')
with open('ab.txt','a',encoding='utf-8') as f:
f.write(it_p.text)
except:
print('出错了') get_context() #调用函数
browser.close() #关闭浏览器
全部代码:
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time num = input('输入总页数:')
st = "pageNo-"
st_nums = st+str(num)
''''''
browser = webdriver.Chrome("D:\python-senium\chromedriver.exe")
browser.get('https://wenku.baidu.com/view/df34290a763231126edb11f9.html')
wait = WebDriverWait(browser,10)
time.sleep(5)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#html-reader-go-more > div.continue-to-read > div.banner-more-btn > span')))
page = browser.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/span")
#js = "document.getElementsByClassName('banner-more-btn').style.visibility='hidden'"
#browser.execute_script(js)
browser.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#html-reader-go-more > div.continue-to-read > div.banner-more-btn > span'))).click()
wait.until(EC.presence_of_element_located((By.ID,st_nums)))
html = browser.page_source soup = BeautifulSoup(html,"html.parser")
def get_context():
try:
its_p = soup.select(".ie-fix p")
for it_p in its_p:
print(it_p.text,end='')
with open('ab.txt','a',encoding='utf-8') as f:
f.write(it_p.text)
except:
print('出错了') get_context()
browser.close()
结果:

缺陷:
这个代码不会去爬取文库中图片信息,所以要是爬取ppt等文库还是不要用了(后面爬ppt的我会再写一篇博客)
提示:
也是后代码会运行出错,主要原因是time.sleep()的时间不够长,可以根据自身情况调整,或者可以多运行几次(如果有其他好的方法可以,希望大佬可以带带我^_^)
python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移的更多相关文章
- python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档 from selenium import webdriver from selenium.webdriver.common.k ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- python+requests爬取百度文库ppt
实验网站:https://wenku.baidu.com/view/c7752014f18583d04964594d.html 在下面这种类型文件中的请求头的url打开后会得到一个页面 你会得到如下图 ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
- Python协程爬取妹子图(内有福利,你懂得~)
项目说明: 1.项目介绍 本项目使用Python提供的协程+scrapy中的选择器的使用(相当好用)实现爬取妹子图的(福利图)图片,这个学会了,某榴什么的.pow(2, 10)是吧! 2.用到的知 ...
- 【Python】Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
随机推荐
- .net core 和 WPF 开发升讯威在线客服与营销系统:使用 WebSocket 实现访客端通信
本系列文章详细介绍使用 .net core 和 WPF 开发 升讯威在线客服与营销系统 的过程.本产品已经成熟稳定并投入商用. 在线演示环境:https://kf.shengxunwei.com 注意 ...
- C中的dll 、lib和exe文件
参考:链接1 链接2 DLL 动态链接库(Dynamic Link Library,缩写为DLL),运行时加载是一个可以被其它应用程序共享的程序模块,其中封装了一些可以被共享的例程和资源.动态链接 ...
- MySQL中的全局锁和表级锁
全局锁和表锁 数据库锁设计的初衷是解决并发出现的一些问题.当出现并发访问的时候,数据库需要合理的控制资源的访问规则.而锁就是访问规则的重要数据结构. 根据锁的范围,分为全局锁.表级锁和行级锁三类. 全 ...
- springBoot实现redis分布式锁
参考:https://blog.csdn.net/weixin_44634197/article/details/108308395 .. 使用redis的set命令带NX(not exist)参数实 ...
- 【Linux】nginx详细说明
Nginx的配置文件nginx.conf配置详解如下: user nginx nginx ; Nginx用户及组:用户 组.window下不指定 worker_processes 8; 工作进程:数目 ...
- webpack知识点整理
作用域 es6里模块化的写法 会存在的问题,变量.方法名字雷同,外部文件调用的时候出现问题 如 a.js里 var a='susan' b.js里 var a='jack' 问题解决方案,添加包裹 a ...
- 在Ubuntu18.04下编译出ffmpeg(支持推流H265成rtmp)
Ubuntu18.04下编译libx264.libx265.libfdk_aac和ffmpeg 一.编译x264库 二.编译fdk-aac库 三.编译x265库 四.编译FFmpeg源码 五.设置环境 ...
- Java并发组件一之CountDownLatch
使用场景: 一个或N个线程,等待其它线程完成某项操作之后才能继续往下执行.CountDownLatch描述的是,一个或N个线程等待其他线程的关系. 使用方法: 设CountDownLatch个数:Co ...
- 知乎社区核心业务 Golang 化实践 - 知乎 https://zhuanlan.zhihu.com/p/48039838
知乎社区核心业务 Golang 化实践 - 知乎 https://zhuanlan.zhihu.com/p/48039838
- 入 Go 必读:大型Go工程的项目结构及实战思考 原创 毛剑 QCon 今天
入 Go 必读:大型Go工程的项目结构及实战思考 原创 毛剑 QCon 今天