吴裕雄 数据挖掘与分析案例实战(2)——python数据结构及方法、控制流、字符串处理、自定义函数
list1 = ['张三','男',33,'江苏','硕士','已婚',['身高178','体重72']]
# 取出第一个元素
print(list1[0])
# 取出第四个元素
print(list1[3])
# 取出最后一个元素
print(list1[6])
# 取出“体重72”这个值
print(list1[6][1])
# 取出最后一个元素
print(list1[-1])
# 取出“身高178”这个值
print(list1[-1][0])
# 取出倒数第三个元素
print(list1[-3])

list2 = ['江苏','安徽','浙江','上海','山东','山西','湖南','湖北']
# 取出“浙江”至“山西”四个元素
print(list2[2:6])
# 取出“安徽”、“上海”、“山西”三个元素
print(list2[1:6:2])
# 取出最后三个元素
print(list2[-3:-1])
# 取出头三个元素
print(list2[:3])
# 取出最后三个元素
print(list2[-3:])
# 取出所有元素
print(list2[::])
# 取出奇数位置的元素
print(list2[::2])

list3 = [1,10,100,1000,10000]
# 在列表末尾添加数字2
list3.append(2)
print(list3)
# 在列表末尾添加20,200,2000,20000四个值
list3.extend([20,200,2000,20000])
print(list3)
# 在数字10后面增加11这个数字
list3.insert(2,11)
print(list3)
# 在10000后面插入['a','b','c']
list3.insert(6,['a','b','c'])
print(list3)
# 删除list3中20000这个元素
list3.pop()
print(list3)
# 删除list3中11这个元素
list3.pop(2)
print(list3)
# 删除list3中的['a', 'b', 'c']
list3.remove(['a', 'b', 'c'])
print(list3)
# 删除list3中所有元素
list3.clear()
print(list3)

list4 = ['洗衣机','冰响','电视机','电脑','空调']
# 将“冰响”修改为“冰箱”
print(list4[1])
list4[1] = '冰箱'
print(list4)

list5 = [7,3,9,11,4,6,10,3,7,4,4,3,6,3]
# 计算列表中元素3的个数
print(list5.count(3))
# 找出元素6所在的位置
print(list5.index(6))
# 列表元素的颠倒
list5.reverse()
print(list5)
# 列表元素的降序
list5.sort(reverse=True)
print(list5)

t = ('a','d','z','a','d','c','a')
# 计数
print(t.count('a'))
# 元素位置
print(t.index('c'))

dict1 = {'姓名':'张三','年龄':33,'性别':'男','子女':{'儿子':'张四','女儿':'张美'},'兴趣':['踢球','游泳','唱歌']}
# 打印字典
print(dict1)
# 取出年龄
print(dict1['年龄'])
# 取出子女中的儿子姓名
print(dict1['子女']['儿子'])
# 取出兴趣中的游泳
print(dict1['兴趣'][1])
# 往字典dict1中增加户籍信息
dict1.setdefault('户籍','合肥')
print(dict1)
# 增加学历信息
dict1.update({'学历':'硕士'})
print(dict1)
# 增加身高信息
dict1['身高'] = 178
print(dict1)
# 删除字典中的户籍信息
dict1.pop('户籍')
print(dict1)
# 删除字典中女儿的姓名
dict1['子女'].pop('女儿')
print(dict1)
# 删除字典中的任意一个元素
dict1.popitem()
print(dict1)
# 清空字典元素
dict1.clear()
print(dict1)
# 将学历改为本科
dict1.update({'学历':'本科'})
print(dict1)
# 将年龄改为35
dict1['年龄'] = 35
print(dict1)
# 将兴趣中的唱歌改为跳舞
# dict1['兴趣'][2] = '跳舞'
# print(dict1)

dict2 = {'电影':['三傻大闹宝莱坞','大话西游之大圣娶亲','疯狂动物城'],
'导演':['拉吉库马尔·希拉尼','刘镇伟','拜伦·霍华德 '],
'评分':[9.1,9.2,9.2]}
# 取出键'评分'所对应的值
print(dict2.get('评分'))
# 取出字典中的所有键
print(dict2.keys())
# 取出字典中的所有值
print(dict2.values())
# 取出字典中的所有键值对
print(dict2.items())

# 返回绝对值
x = -3
if x >= 0:
print(x)
else:
print(-1*x)
# 返回成绩对应的等级
score = 68
if score < 60:
print('不及格')
elif score < 70:
print('合格')
elif score < 80:
print('良好')
else:
print('优秀')

# 将列表中的每个元素作平方加1处理
list6 = [1,5,2,8,10,13,17,4,6]
result = []
for i in list6:
y = i ** 2 + 1
result.append(y)
print(result)
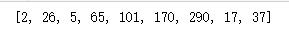
# 计算1到100之间的偶数和
s1_100 = 0
for i in range(1,101):
if i % 2 == 0:
s1_100 = s1_100 + i
else:
pass
print('1到100之间的偶数和为%s'%s1_100)
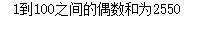
# 对列表中的偶数作三次方减10的处理
list7 = [3,1,18,13,22,17,23,14,19,28,16]
result = [i ** 3 - 10 for i in list7 if i % 2 == 0]
print(result)
# 使用for循环登录某手机银行APP
for i in range(1,6):
user = input('请输入用户名:')
password = int(input('请输入密码:'))
if (user == 'test') & (password == 123):
print('登录成功!')
break
else:
if i < 5:
print('错误!您今日还剩%d次输入机会。' %(5-i))
else:
print('请24小时后再尝试登录!')

# 使用while循环登录某邮箱账号
while True:
user = input('请输入用户名:')
password = int(input('请输入密码:'))
if (user == 'test') & (password == 123):
print('登录成功!')
break
else:
print('您输入的用户名或密码错误!')

print('dag%.2f' %2.123)
dag2.12
# 单引号构造字符串
string1 = '"commentTime":"2018-01-26 08:59:30","content":"包装良心!馅料新鲜!还会回购"'
# 双引号构造字符串
string2 = "ymd:'2017-01-01',bWendu:'5℃',yWendu:'-3℃',tianqi:'霾~晴',fengxiang:'南风',aqiInfo:'严重污染'"
# 三引号构造字符串
string3 = ''''nickName':"美美",'content':"环境不错,服务态度超好,就是有点小贵",'createTimestring':"2017-09-30"'''
string4 = '''据了解,持续降雪造成安徽部分地区农房倒损、种植养殖业大棚损毁,
其中合肥、马鞍山、铜陵3市倒塌农房8间、紧急转移安置8人。'''
print(string1)
print(string2)
print(string3)
print(string4)

# 获取身份证号码中的出生日期
print('123456198901017890'[6:14])
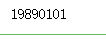
# 将手机号中的中间四位替换为四颗星
tel = '13612345678'
print(tel.replace(tel[3:7],'****'))
# 将邮箱按@符分隔开
print('12345@qq.com'.split('@'))
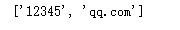
# 将Python的每个字母用减号连接
print('-'.join('Python'))

# 删除" 今天星期日 "的首尾空白
print(" 今天星期日 ".strip())
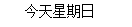
# 删除" 今天星期日 "的左边空白
print(" 今天星期日 ".lstrip())

# 删除" 今天星期日 "的右边空白
print(" 今天星期日 ".rstrip())

# 计算子串“中国”在字符串中的个数
string5 = '中国方案引领世界前行,展现了中国应势而为、勇于担当的大国引领作用!'
print(string5.count('中国'))
2
# 查询"Python"单词所在的位置
string6 = '我是一名Python用户,Python给我的工作带来了很多便捷。'
print(string6.index('Python'))
print(string6.find('Python'))
4
4
# 字符串是否以“2018年”开头
string7 = '2017年匆匆走过,迎来崭新的2018年'
print(string7.startswith('2018年'))
# 字符串是否以“2018年”年结尾
print(string7.endswith('2018年'))
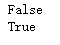
# 导入第三方包
import re
# 取出出字符中所有的天气状态
string8 = "{ymd:'2018-01-01',tianqi:'晴',aqiInfo:'轻度污染'},{ymd:'2018-01-02',tianqi:'阴~小雨',aqiInfo:'优'},{ymd:'2018-01-03',tianqi:'小雨~中雨',aqiInfo:'优'},{ymd:'2018-01-04',tianqi:'中雨~小雨',aqiInfo:'优'}"
print(re.findall("tianqi:'(.*?)'", string8))
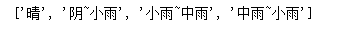
# 取出所有含O字母的单词
string9 = 'Together, we discovered that a free market only thrives when there are rules to ensure competition and fair play, Our celebration of initiative and enterprise'
print(re.findall('\w*o\w*',string9, flags = re.I))

# 将标点符号、数字和字母删除
string10 = '据悉,这次发运的4台蒸汽冷凝罐属于国际热核聚变实验堆(ITER)项目的核二级压力设备,先后完成了压力试验、真空试验、氦气检漏试验、千斤顶试验、吊耳载荷试验、叠装试验等验收试验。'
print(re.sub('[,。、a-zA-Z0-9()]','',string10))
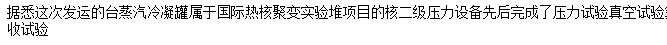
# 将每一部分的内容分割开
string11 = '2室2厅 | 101.62平 | 低区/7层 | 朝南 \n 上海未来 - 浦东 - 金杨 - 2005年建'
split = re.split('[-\|\n]', string11)
print(split)
split_strip = [i.strip() for i in split]
print(split_strip)

# 统计列表中每个元素的频次
list6 = ['A','A','B','A','A','B','C','B','C','B','B','D','C']
# 构建空字典,用于频次统计数据的存储
dict3 = {}
# 循环计算
for i in set(list6):
dict3[i] = list6.count(i)
print(dict3)
# 取出字典中的键值对
key_value = list(dict3.items())
print(key_value)
# 列表排序
key_value.sort()
print(key_value)
# 按频次高低排序
key_value.sort(key = lambda x : x[1], reverse=True)
print(key_value)

# 猜数字
def game(min,max):
import random
number = random.randint(min,max) # 随机生成一个需要猜的数字
while True:
guess = float(input('请在%d到%d之间猜一个数字: ' %(min, max)))
if guess < number:
min = guess
print('不好意思,你猜的的数偏小了!请在%d到%d之间猜一个数!' %(min,max))
elif guess > number:
max = guess
print('不好意思,你猜的的数偏大了!请在%d到%d之间猜一个数!' %(min,max))
else:
print('恭喜你猜对了!')
print('游戏结束!')
break
# 调用函数
game(10,20)
# 缺少位置参数值的传递
game(min = 10)

# 计算1到n的平方和
def square_sum(n, p = 2):
result = sum([i ** p for i in range(1,n+1)])
return(n,p,result)
print('1到%d的%d次方和为%d!' %square_sum(200))
print('1到%d的%d次方和为%d!' %square_sum(200,3))

# 两个数的求和
def add(a,b):
s = sum([a,b])
return(a,b,s)
print('%d加%d的和为%d!' %add(10,13))
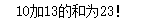
# 任意个数的数据求和
def adds(*args):
print(args)
s = sum(args)
return(s)
print('和为%d!' %adds(10,13,7,8,2))
print('和为%d!' %adds(7,10,23,44,65,12,17))

# 关键字参数
def info_collection(tel, birthday, **kwargs):
user_info = {} # 构造空字典,用于存储用户信息
user_info['tel'] = tel
user_info['birthday'] = birthday
user_info.update(kwargs)
# 用户信息返回
return(user_info)
# 调用函数
info = info_collection(13612345678,'1990-01-01',nickname='月亮',gender = '女',edu = '硕士',income = 15000,add = '上海市浦东新区',interest = ['游泳','唱歌','看电影'])
print(info)

# 导入第三方包
import requests
import time
import random
import pandas as pd
import re
# 生成请求头
headers = {
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Cookie':'widget_dz_id=54511; widget_dz_cityValues=,; timeerror=1; defaultCityID=54511; defaultCityName=%u5317%u4EAC; Hm_lvt_a3f2879f6b3620a363bec646b7a8bcdd=1516245199; Hm_lpvt_a3f2879f6b3620a363bec646b7a8bcdd=1516245199; addFavorite=clicked',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3236.0 Safari/537.36'
}
# 生成所有需要抓取的链接
urls = []
for year in range(2011,2018):
for month in range(1,13):
if year <= 2016:
urls.append('http://tianqi.2345.com/t/wea_history/js/58362_%s%s.js' %(year,month))
else:
if month<10:
urls.append('http://tianqi.2345.com/t/wea_history/js/%s0%s/58362_%s0%s.js' %(year,month,year,month))
else:
urls.append('http://tianqi.2345.com/t/wea_history/js/%s%s/58362_%s%s.js' %(year,month,year,month))
print(urls)
# 循环并通过正则匹配获取相关数据
info = []
for url in urls:
seconds = random.randint(3,6)
response = requests.get(url, headers = headers).text
ymd = re.findall("ymd:'(.*?)',",response)
high = re.findall("bWendu:'(.*?)℃',",response)
low = re.findall("yWendu:'(.*?)℃',",response)
tianqi = re.findall("tianqi:'(.*?)',",response)
fengxiang = re.findall("fengxiang:'(.*?)',",response)
fengli = re.findall(",fengli:'(.*?)'",response)
aqi = re.findall("aqi:'(.*?)',",response)
aqiInfo = re.findall("aqiInfo:'(.*?)',",response)
aqiLevel = re.findall(",aqiLevel:'(.*?)'",response)
# 由于2011~2015没有空气质量相关的数据,故需要分开处理
if len(aqi) == 0:
aqi = None
aqiInfo = None
aqiLevel = None
info.append(pd.DataFrame({'ymd':ymd,'high':high,'low':low,'tianqi':tianqi,'fengxiang':fengxiang,'fengli':fengli,'aqi':aqi,'aqiInfo':aqiInfo,'aqiLevel':aqiLevel}))
else:
info.append(pd.DataFrame({'ymd':ymd,'high':high,'low':low,'tianqi':tianqi,'fengxiang':fengxiang,'fengli':fengli,'aqi':aqi,'aqiInfo':aqiInfo,'aqiLevel':aqiLevel}))
time.sleep(seconds)

# 生成数据表
weather = pd.concat(info)
print(type(weather))
# 数据导出
weather.to_csv('E:\\weather.csv',index = False)
吴裕雄 数据挖掘与分析案例实战(2)——python数据结构及方法、控制流、字符串处理、自定义函数的更多相关文章
- 吴裕雄 数据挖掘与分析案例实战(15)——DBSCAN与层次聚类分析
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfr ...
- 吴裕雄 数据挖掘与分析案例实战(14)——Kmeans聚类分析
# 导入第三方包import pandas as pdimport numpy as np import matplotlib.pyplot as pltfrom sklearn.cluster im ...
- 吴裕雄 数据挖掘与分析案例实战(13)——GBDT模型的应用
# 导入第三方包import pandas as pdimport matplotlib.pyplot as plt # 读入数据default = pd.read_excel(r'F:\\pytho ...
- 吴裕雄 数据挖掘与分析案例实战(12)——SVM模型的应用
import pandas as pd # 导入第三方模块from sklearn import svmfrom sklearn import model_selectionfrom sklearn ...
- 吴裕雄 数据挖掘与分析案例实战(10)——KNN模型的应用
# 导入第三方包import pandas as pd # 导入数据Knowledge = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\1 ...
- 吴裕雄 数据挖掘与分析案例实战(8)——Logistic回归分类模型
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt # 自定义绘制ks曲线的函数def plot_ks(y_tes ...
- 吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import mod ...
- 吴裕雄 数据挖掘与分析案例实战(5)——python数据可视化
# 饼图的绘制# 导入第三方模块import matplotlibimport matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['S ...
- 吴裕雄 数据挖掘与分析案例实战(4)——python数据处理工具:Pandas
# 导入模块import pandas as pdimport numpy as np # 构造序列gdp1 = pd.Series([2.8,3.01,8.99,8.59,5.18])print(g ...
- 吴裕雄 数据挖掘与分析案例实战(3)——python数值计算工具:Numpy
# 导入模块,并重命名为npimport numpy as np# 单个列表创建一维数组arr1 = np.array([3,10,8,7,34,11,28,72])print('一维数组:\n',a ...
随机推荐
- Django 命令行工具django-admin.py与manage.py
django-admin.py是Django的一个用于管理任务的命令行工具,manage.py是对django-admin.py的简单包装,每个Django Project里面都会包含一个manage ...
- php对象的实现
1.对象的数据结构非常简单 typedef struct _zend_object zend_object; struct _zend_object { zend_refcounted_h gc; / ...
- ApacheKylin笔记
基本没有什么难度,只要照着官网上配置就行,这里有以下几点需要注意: HBase一定要用2.0以下的,切记.否则会报找不到方法的错误! 需要配置修改kylin.properties文件里的spark配置 ...
- Java高并发综合
这篇文章是研一刚入学时写的,今天整理草稿时才被我挖出来.当时混混沌沌的面试,记下来了一些并发的面试问题,很多还没有回答.到现在也学习了不少并发的知识,回过头来看这些问题和当时整理的答案,漏洞百出又十分 ...
- pycharm中配置pep8
Pycharm本身是有pep8风格检测的,当你敲得代码中不符合规范时,会有下划波浪线提示.如何让代码修改为符合规范,去掉这些难看的波浪线呢? 1.安装autopep8 pip install aut ...
- Robot常用Library安装
Python-Library: yum install -y mysql-devel python-devel python-setuptools pip install MySQL-python p ...
- Delphi7到Delphi XE2的升级历程
1.PChar 转为PAnsiChar; 2.第三方控件的安装 SuiPack不能直接点击InStall.exe安装,需要打开DPK文件安装: SuiPack安装之后程序编译会报错,resHandle ...
- storm项目架构分析
storm是一条一条数据处理,spark是一批数据处理的,storm才是真正意义的实时数据处理. 1.fileBeat类似flume用来采集日志的,fileBeat是轻量级的,对性能消化不大,而flu ...
- vb 使用StreamWriter书写流写出数据并生成文件
sql = "Select case when date ='' then '0'else CONVERT(varchar(100), date, 101) end as date,case ...
- JS修改属性,六种数据类型
JS修改属性 一般修改单个属性是通过JS修改的,比较方便.改多个属性通过css样式改更方便. 1.特殊:通过JS修改包含"-"符号的属性,例如margin-top // 特殊 修改 ...