[Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一、介绍
本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/hangye/index.html)的信息
二、网站信息
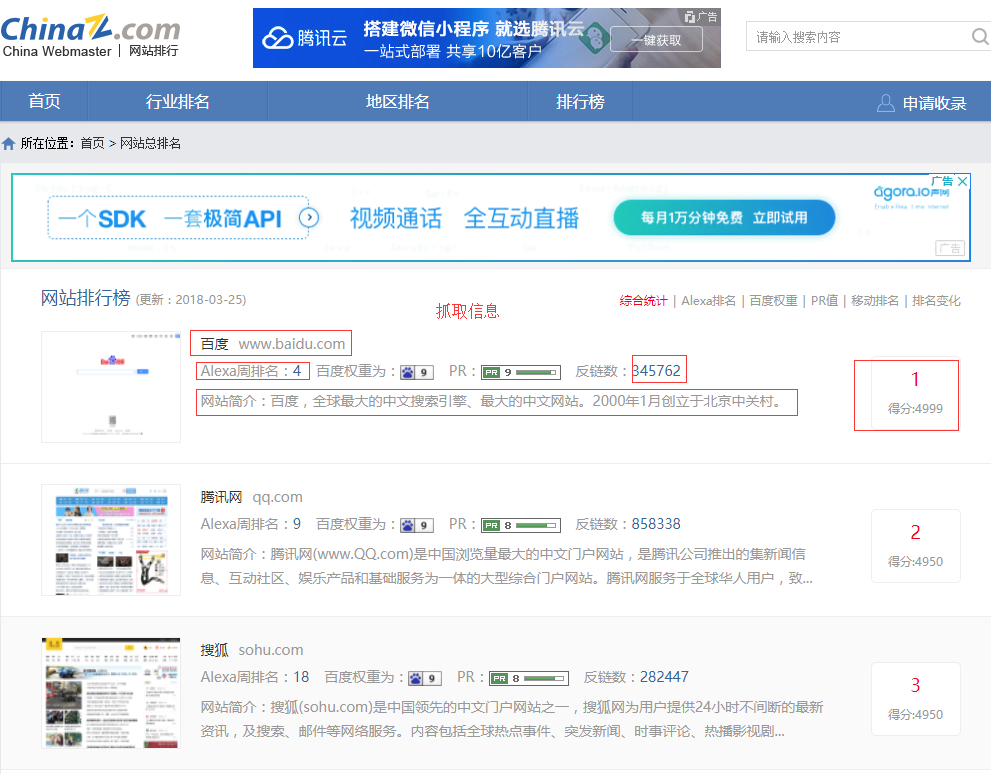
三、数据抓取
针对上面的网站信息,来进行抓取
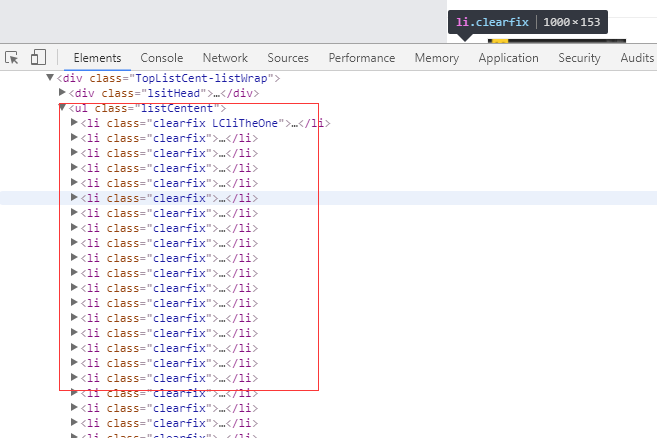
1、首先抓取信息列表
抓取代码:Elements = doc('li[class^="clearfix"]') 类似信息
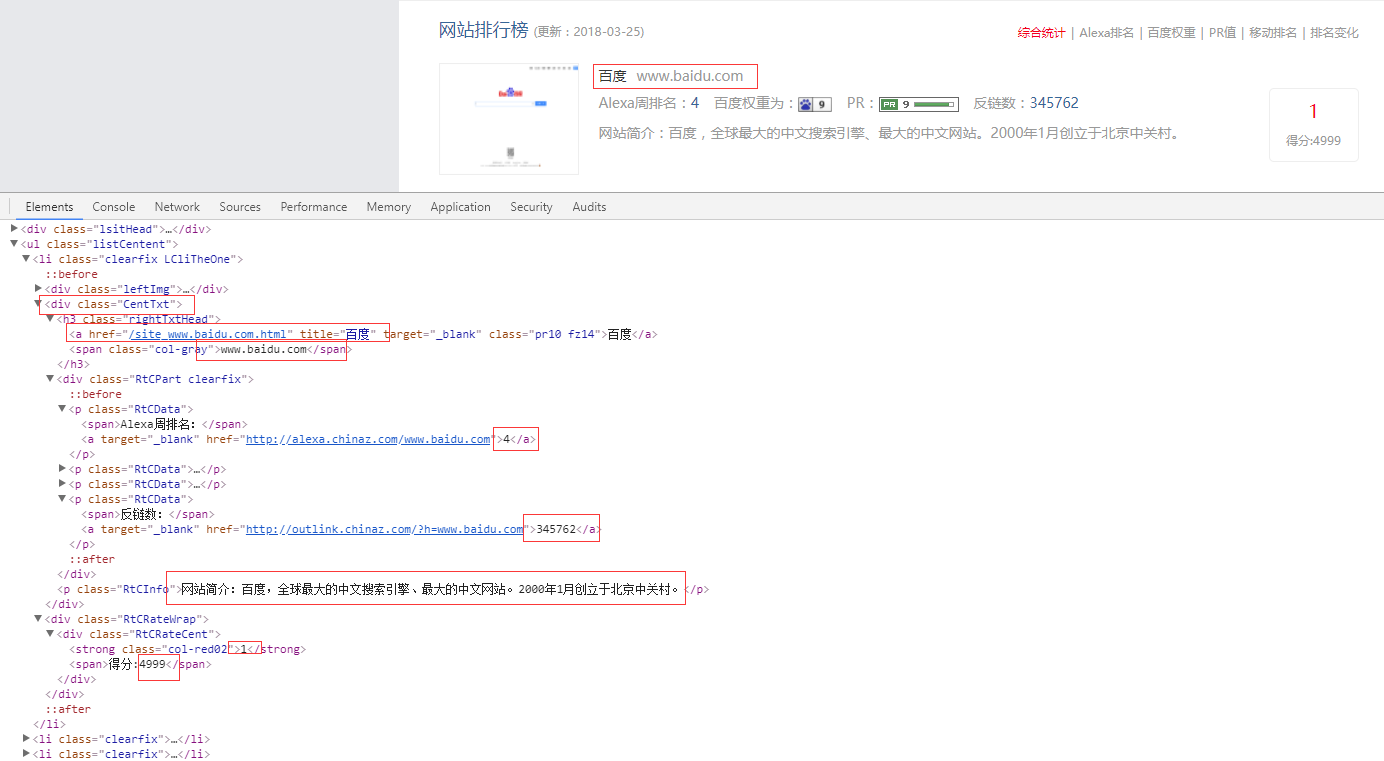
2、网站名称,域名,网址
netElement = element.find('div[class="CentTxt"]').find('h3').find('a')
netName = netElement.attr('title').encode('utf8')
netUrl = 'http://top.chinaz.com' + netElement.attr('href').encode('utf8')
domainName = element.find('div[class="CentTxt"]').find('h3').find('span').text().encode('utf8')
3、Alexa周排名,反链数,网站描述
netinfo = element.find('div[class="RtCPart clearfix"]').text().encode('utf8')
4、排名,得分
netOrder = element.find('div[class="RtCRateCent"]').find('strong').text().encode('utf8')
netScore = element.find('div[class="RtCRateCent"]').find('span').text().encode('utf8')
四、具体思路
对于抓取分类网站排名信息思路如:
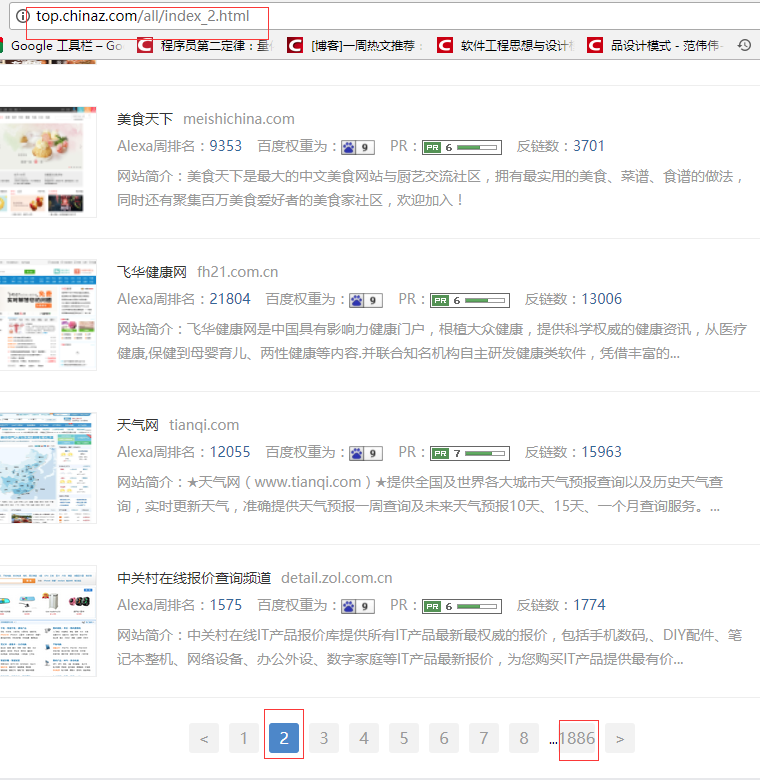
1、首先抓取一级分类名称(包括拼音和中文名称),分类对应的url, 该分类数据的总页数,保存到数据表category
2、根据分类数据的总页数,计算出该分类的所有网页的url, 并把 category, cncategory, url, index,iscrawl(是否抓取,默认是0:未抓取,1:已抓取) 保存至数据表categoryall中
3、通过获取categoryall表中每种分类的url,开始抓取每页数据,每页抓取完成后修改iscrawl =1,避免重复抓取。抓取每个数据后把相关数据保存到categorydata表中,
在保存之前通过 netname,domainname,category三个字段来判断是否有重复数据,避免保存重复。
3、二级分类网站排名信息同上。
五、实现代码
# coding=utf-8
import os
import re
from selenium import webdriver
from datetime import datetime,timedelta
import selenium.webdriver.support.ui as ui
from selenium.common.exceptions import TimeoutException
import time
from pyquery import PyQuery as pq
import re
import mongoDB
import hyData class hyTotal: def __init__(self):
#通过配置文件获取IEDriverServer.exe路径
# IEDriverServer ='C:\Program Files\Internet Explorer\IEDriverServer.exe'
# self.driver = webdriver.Ie(IEDriverServer)
# self.driver.maximize_window()
self.driver = webdriver.PhantomJS(service_args=['--load-images=false'])
self.driver.set_page_load_timeout(10)
self.driver.maximize_window()
self.db = mongoDB.mongoDbBase() def saveurls(self):
urls = []
urls.append('http://top.chinaz.com/all/index.html')
for i in range(2, 1888):
urls.append('http://top.chinaz.com/all/index_' + str(i) + '.html') self.db.SaveTotalUrls(urls) def WriteLog(self, message,date,dir):
fileName = os.path.join(os.getcwd(), 'hangye/total/' + date + '-' + dir + '.txt')
with open(fileName, 'a') as f:
f.write(message) def CatchData(self): urlIndex = 0
urls = self.db.GetTotalUrls()
# {'_id': 0, 'url': 1,'category':1,'index':1}
lst = []
for u in urls:
url = u['url']
urlIndex = u['index']
lst.append('{0},{1}'.format(url,urlIndex))
urls.close()
for u in lst:
url = u.split(',')[0]
urlIndex = u.split(',')[1] try:
self.driver.get(url)
time.sleep(2)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
# Elements = doc("div[@id='text_box_0']/dl/dd")
Elements = doc('li[class^="clearfix"]')
message = ''
# for element in Elements:
data_list = []
for element in Elements.items():
hyobj = hyData.hyData()
# column1Element = element.find('div[@class="text"]/h3/a')
# 网站名称,域名,网址
# netElement = element.find_element_by_xpath("//div[@class='CentTxt']/h3/a")
netElement = element.find('div[class="CentTxt"]').find('h3').find('a')
# netName = nextElement.get_attribute('title').encode('utf8')
netName = netElement.attr('title').encode('utf8').replace('\n','').replace(',',',') netUrl = 'http://top.chinaz.com' + netElement.attr('href').encode('utf8') # domainName = element.find_element_by_xpath('//div[class="CentTxt"]/h3/span').text.encode('utf8')
domainName = element.find('div[class="CentTxt"]').find('h3').find('span').text().encode('utf8') # Alexa周排名,反链数,网站描述
netinfo = element.find('div[class="RtCPart clearfix"]').text().encode('utf8')
pattern = re.compile("\d+")
ts = pattern.findall(netinfo)
alexaOrder = ''
antichainCount = ''
if ts and len(ts) == 2:
alexaOrder = ts[0]
antichainCount = ts[1] netDescription = element.find('p[class="RtCInfo"]').text().encode('utf8')
netDescription = netDescription.replace('网站简介:', '').replace(',', ',').replace('\n', '') # 排名,得分
netOrder = element.find('div[class="RtCRateCent"]').find('strong').text().encode('utf8')
netScore = element.find('div[class="RtCRateCent"]').find('span').text().encode('utf8')
netScore = netScore.replace('得分:', '') hyobj.setNetName(netName)
hyobj.setDomainName(domainName)
hyobj.setNetRank(netOrder)
hyobj.setNetScore(netScore)
# print alexaOrder
hyobj.setAlexaRank(alexaOrder)
hyobj.setAntichainCount(antichainCount)
hyobj.setNetUrl(netUrl)
hyobj.setNetDescription(netDescription)
hyobj.setPageIndex(urlIndex)
data_list.append(hyobj)
self.db.SaveTotalData(data_list)
self.db.SetTotalState(url)
print url
except TimeoutException,e:
print 'timeout url: '+url self.driver.close()
self.driver.quit() def exportHyTotal(self):
dataRows = self.db.GetTotalData()
for dataRow in dataRows:
pageIndex = int(dataRow['pageIndex'].encode('utf8'))
netname = dataRow['netname'].encode('utf8')
domainname = dataRow['domainname'].encode('utf8')
netrank = dataRow['netrank'] netscore = dataRow['netscore']
alexarank = dataRow['alexarank']
antichaincount = dataRow['antichaincount'] neturl = dataRow['neturl'].encode('utf8')
netdescription = dataRow['netdescription'].encode('utf8') # 网站名称,网站域名,排名,得分,alexa排名,反链数,网站简介,网站类型
message = '\n{0},{1},{2},{3},{4},{5},{6},{7}'.format(netname, domainname,
netrank,
netscore, alexarank,
antichaincount, neturl,
netdescription)
date = time.strftime('%Y-%m-%d')
dir = str((pageIndex/50+1)*50)
self.WriteLog(message,date,dir) obj = hyTotal()
# obj.saveurls() # obj.CatchData()
obj.exportHyTotal()
# coding=utf-8
import os
from pymongo import MongoClient
from pymongo import ASCENDING, DESCENDING
import codecs
import time
import columnData
import datetime
import re
import hyData
import categoryItem class mongoDbBase:
# def __init__(self, databaseIp = '127.0.0.1',databasePort = 27017,user = "ott",password= "ott", mongodbName='OTT_DB'):
def __init__(self, connstr='mongodb://ott:ott@127.0.0.1:27017/', mongodbName='OTT'):
# client = MongoClient(connstr)
# self.db = client[mongodbName]
client = MongoClient('127.0.0.1', 27017)
self.db = client.OTT
self.db.authenticate('ott', 'ott') def SaveTotalUrls(self, urls):
# self.db.hytotalurls.drop()
index = 1
lst = []
for url in urls:
dictM = {'url': url, 'iscrawl': 0, 'index': index}
lst.append(dictM)
index += 1
self.db.totalurls.insert(lst) def SetTotalState(self,url):
self.db.totalurls.update({'url': url}, {'$set': {'iscrawl': 1}}) def GetTotalUrls(self):
urls = self.db.totalurls.find({'iscrawl': 0}, {'_id': 0, 'url': 1, 'index': 1}).sort('index',ASCENDING)
return urls def SaveTotalData(self, hydata_list):
lst = []
for hyobj in hydata_list:
count = self.db.totaldata.find(
{'netname': hyobj.getNetName(), 'domainname': hyobj.getDomainName()}).count()
if count == 0:
dictM = {'netname': hyobj.getNetName(),
'domainname': hyobj.getDomainName(),
'netrank': hyobj.getNetRank(),
'netscore': hyobj.getNetScore(),
'alexarank': hyobj.getAlexaRank(),
'antichaincount': hyobj.getAntichainCount(),
'neturl': hyobj.getNetUrl(),
'netdescription': hyobj.getNetDescription(),
'pageIndex': hyobj.getPageIndex()}
lst.append(dictM)
self.db.totaldata.insert(lst) def GetTotalData(self):
rows = self.db.totaldata.find({},{'_id': 0}).sort('netrank',ASCENDING)
return rows def SaveCategory(self, category,cncategory,url):
# self.db.category.drop()
dictM = {'category': category, 'cncategory': cncategory, 'url': url}
self.db.category.insert(dictM) def GetCategory(self):
categorys =self.db.category.find({},{'_id':0,'category':1,'cncategory':1,'url':1})
return categorys def UpdateCategoryPageCount(self, category,count):
self.db.category.update({"category":category},{'$set':{'count':count}}) def GetCategories(self):
categorys =self.db.category.find({},{'_id':0,'category':1,'url':1,'count':1,'cncategory':1}).sort('index',ASCENDING)
return categorys def SaveCategoryUrls(self,categoryItem_list):
# self.db.categoryall.drop()
lst = []
for citem in categoryItem_list:
dictM ={'category':citem.getCategroy(),'cncategory':citem.getCnCategroy(),'url':citem.getUrl(),'index':citem.getUrlIndex(),'iscrawl':0}
lst.append(dictM)
self.db.categoryall.insert(lst) def GetCategoryUrl(self):
categorys = self.db.categoryall.find({'iscrawl':0}, {'_id': 0, 'url': 1, 'index': 1,'category':1,'cncategory':1}).sort(
'index', ASCENDING)
return categorys def SetCategoryState(self,url):
self.db.categoryall.update({'url': url}, {'$set': {'iscrawl': 1}}) def SaveCategoryData(self, category_list):
lst = []
for hyobj in category_list:
count = self.db.categorydata.find(
{'netname': hyobj.getNetName(), 'domainname': hyobj.getDomainName(), 'category': hyobj.getCategory()}).count()
if count == 0:
dictM = {'netname': hyobj.getNetName(),
'domainname': hyobj.getDomainName(),
'netrank': hyobj.getNetRank(),
'netscore': hyobj.getNetScore(),
'alexarank': hyobj.getAlexaRank(),
'antichaincount': hyobj.getAntichainCount(),
'neturl': hyobj.getNetUrl(),
'netdescription': hyobj.getNetDescription(),
'category': hyobj.getCategory(),
'cncategory': hyobj.getCnCategory()}
lst.append(dictM)
if len(lst)>0:
self.db.categorydata.insert(lst) def GetCategoryData(self):
rows = self.db.categorydata.find({}, {'_id': 0}).sort('category',ASCENDING)
return rows def SaveSubCategory(self, category_list):
# self.db.subcategory.drop()
lst = []
for sub in category_list:
category = sub.split(',')[0]
cncategory = sub.split(',')[1]
subcategory = sub.split(',')[2]
subcncategory = sub.split(',')[3]
url = sub.split(',')[4]
dictM = {'category': category, 'cncategory': cncategory,'subcategory': subcategory, 'subcncategory': subcncategory, 'url': url,'count':0}
lst.append(dictM)
self.db.subcategory.insert(lst) def GetSubCategory(self):
categorys =self.db.subcategory.find({'count':0},{'_id':0,'category':1,'url':1})
return categorys def UpdateSubCategoryPageCount(self, url,count):
self.db.subcategory.update({"url":url},{'$set':{'count':count}}) def GetSubCategories(self):
categorys =self.db.subcategory.find({},{'_id':0,'category':1,'cncategory':1,'subcategory':1,'subcncategory':1,'url':1,'count':1})
return categorys def SaveSubCategoryUrls(self,categoryItem_list):
# self.db.subcategoryall.drop()
lst = []
for citem in categoryItem_list:
dictM ={'category':citem.getCategroy(),'cncategory':citem.getCnCategroy(),'url':citem.getUrl(),
'index':citem.getUrlIndex(),'iscrawl':0,'subcategory':citem.getSubCategroy(),'subcncategory':citem.getSubCnCategory()}
lst.append(dictM)
self.db.subcategoryall.insert(lst) def GetSubCategoryUrl(self):
categorys = self.db.subcategoryall.find({'iscrawl': 0}, {'_id': 0, 'url': 1, 'index': 1, 'category':1,'subcategory': 1, 'cncategory':1,'subcncategory': 1}).sort(
'index', ASCENDING)
return categorys def SaveSubCategoryData(self, subcategory_list):
lst = []
for hyobj in subcategory_list:
count = self.db.subcategorydata.find(
{'netname': hyobj.getNetName(), 'domainname': hyobj.getDomainName(), 'category': hyobj.getCategory()}).count()
if count == 0:
dictM = {'netname': hyobj.getNetName(),
'domainname': hyobj.getDomainName(),
'netrank': hyobj.getNetRank(),
'netscore': hyobj.getNetScore(),
'alexarank': hyobj.getAlexaRank(),
'antichaincount': hyobj.getAntichainCount(),
'neturl': hyobj.getNetUrl(),
'netdescription': hyobj.getNetDescription(),
'category': hyobj.getCategory(),
'cncategory': hyobj.getCnCategory()
}
lst.append(dictM)
# 批量插入
if len(lst) > 0:
self.db.subcategorydata.insert(lst) def SetSubCategoryState(self, url):
self.db.subcategoryall.update({'url': url}, {'$set': {'iscrawl': 1}}) def GetSubCategoryData(self):
# [(‘age‘,pymongo.DESCENDING),('name',pymongo.ASCENDING)]
rows = self.db.subcategorydata.find({}, {'_id': 0}).sort([('category',ASCENDING),('netrank',ASCENDING)])
return rows
# d = mongoDbBase() # urls = []
# urls.append('abc')
# # d.SaveUrls(urls)
# d.SetUrlCrawlState(urls)
分类抓取实现代码 (mongodb)
# coding=utf-8
import os
from pymongo import MongoClient
from pymongo import ASCENDING, DESCENDING
import codecs
import time
import columnData
import datetime
import re
import hyData
import categoryItem class mongoDbBase:
# def __init__(self, databaseIp = '127.0.0.1',databasePort = 27017,user = "ott",password= "ott", mongodbName='OTT_DB'):
def __init__(self, connstr='mongodb://ott:ott@127.0.0.1:27017/', mongodbName='OTT'):
# client = MongoClient(connstr)
# self.db = client[mongodbName]
client = MongoClient('127.0.0.1', 27017)
self.db = client.OTT
self.db.authenticate('ott', 'ott') def SaveHyTotalUrls(self, urls):
# self.db.hytotalurls.drop()
index = 0
for url in urls:
dictM = {'url': url, 'iscrawl': '', 'index': index + 1}
self.db.hytotalurls.insert(dictM)
index += 1 def SetHyTotalState(self,url):
self.db.hytotalurls.update({'url': url}, {'$set': {'iscrawl': ''}}) def GetHyTotalUrls(self):
urls = self.db.hytotalurls.find({'iscrawl': ''}, {'_id': 0, 'url': 1, 'index': 1}).sort('index',ASCENDING)
return urls def SaveHyTotalData(self, hyobj):
count = self.db.hytotaldata.find({'netname': hyobj.getNetName(),'domainname':hyobj.getDomainName()}).count()
if count == 0:
dictM = {'netname': hyobj.getNetName(),
'domainname': hyobj.getDomainName(),
'netrank': hyobj.getNetRank(),
'netscore': hyobj.getNetScore(),
'alexarank': hyobj.getAlexaRank(),
'antichaincount': hyobj.getAntichainCount(),
'neturl': hyobj.getNetUrl(),
'netdescription': hyobj.getNetDescription(),
'pageIndex':hyobj.getPageIndex()}
self.db.hytotaldata.insert(dictM) def GetHyTotalData(self):
rows = self.db.hytotaldata.find({},{'_id': 0}).sort('netrank',ASCENDING)
return rows def SaveHyCategoryUrls(self, urls,categories):
index = 0
seIndex = 0
for url in urls:
category = categories[seIndex]
count = self.db.hyurls.find({'url': url}).count()
if count == 0:
dictM = {'url': url, 'iscrawl': '', 'category': category, 'index': index+1}
self.db.hyurls.insert(dictM)
index += 1
seIndex += 1 def GetHyCategoryUrls(self):
urls = self.db.hyurls.find({'iscrawl': ''}, {'_id': 0, 'url': 1,'category':1,'index':1}).sort('index',ASCENDING)
return urls def SetHyUrlCrawlState(self,url):
self.db.hyurls.update({'url': url}, {'$set': {'iscrawl': ''}}) def SaveHyCategoryData(self, hyobj):
count = self.db.hydata.find({'netname': hyobj.getNetName(),'domainname':hyobj.getDomainName()}).count()
if count == 0:
dictM = {'netname': hyobj.getNetName(),
'domainname': hyobj.getDomainName(),
'netrank': hyobj.getNetRank(),
'netscore': hyobj.getNetScore(),
'alexarank': hyobj.getAlexaRank(),
'antichaincount': hyobj.getAntichainCount(),
'neturl': hyobj.getNetUrl(),
'netdescription': hyobj.getNetDescription(),
'category': hyobj.getCategory()}
self.db.hydata.insert(dictM) def GetHyCategoryData(self,category):
rows = self.db.hydata.find({'category':category}, {'_id': 0}).sort('netrank',ASCENDING)
return rows def SaveCategory(self, category,cncategory,url):
# self.db.category.drop()
dictM = {'category': category, 'cncategory': cncategory, 'url': url}
self.db.category.insert(dictM) def GetCategory(self):
categorys =self.db.category.find({},{'_id':0,'category':1,'cncategory':1,'url':1})
return categorys def UpdateCategoryPageCount(self, category,count):
self.db.category.update({"category":category},{'$set':{'count':count}}) def GetCategories(self):
categorys =self.db.category.find({},{'_id':0,'category':1,'url':1,'count':1,'cncategory':1}).sort('index',ASCENDING)
return categorys def SaveCategoryUrls(self,categoryItem_list):
# self.db.categoryall.drop()
lst = []
for citem in categoryItem_list:
dictM ={'category':citem.getCategroy(),'cncategory':citem.getCnCategroy(),'url':citem.getUrl(),'index':citem.getUrlIndex(),'iscrawl':0}
lst.append(dictM)
self.db.categoryall.insert(lst) def GetCategoryUrl(self):
categorys = self.db.categoryall.find({'iscrawl':0}, {'_id': 0, 'url': 1, 'index': 1,'category':1,'cncategory':1}).sort(
'index', ASCENDING)
return categorys def SetCategoryState(self,url):
self.db.categoryall.update({'url': url}, {'$set': {'iscrawl': 1}}) def SaveCategoryData(self, category_list):
lst = []
for hyobj in category_list:
count = self.db.categorydata.find(
{'netname': hyobj.getNetName(), 'domainname': hyobj.getDomainName(), 'category': hyobj.getCategory()}).count()
if count == 0:
dictM = {'netname': hyobj.getNetName(),
'domainname': hyobj.getDomainName(),
'netrank': hyobj.getNetRank(),
'netscore': hyobj.getNetScore(),
'alexarank': hyobj.getAlexaRank(),
'antichaincount': hyobj.getAntichainCount(),
'neturl': hyobj.getNetUrl(),
'netdescription': hyobj.getNetDescription(),
'category': hyobj.getCategory(),
'cncategory': hyobj.getCnCategory()}
lst.append(dictM)
if len(lst)>0:
self.db.categorydata.insert(lst) def GetCategoryData(self):
rows = self.db.categorydata.find({}, {'_id': 0}).sort('category',ASCENDING)
return rows def SaveSubCategory(self, category_list):
# self.db.subcategory.drop()
lst = []
for sub in category_list:
category = sub.split(',')[0]
cncategory = sub.split(',')[1]
subcategory = sub.split(',')[2]
subcncategory = sub.split(',')[3]
url = sub.split(',')[4]
dictM = {'category': category, 'cncategory': cncategory,'subcategory': subcategory, 'subcncategory': subcncategory, 'url': url,'count':0}
lst.append(dictM)
self.db.subcategory.insert(lst) def GetSubCategory(self):
categorys =self.db.subcategory.find({'count':0},{'_id':0,'category':1,'url':1})
return categorys def UpdateSubCategoryPageCount(self, url,count):
self.db.subcategory.update({"url":url},{'$set':{'count':count}}) def GetSubCategories(self):
categorys =self.db.subcategory.find({},{'_id':0,'category':1,'cncategory':1,'subcategory':1,'subcncategory':1,'url':1,'count':1})
return categorys def SaveSubCategoryUrls(self,categoryItem_list):
# self.db.subcategoryall.drop()
lst = []
for citem in categoryItem_list:
dictM ={'category':citem.getCategroy(),'cncategory':citem.getCnCategroy(),'url':citem.getUrl(),
'index':citem.getUrlIndex(),'iscrawl':0,'subcategory':citem.getSubCategroy(),'subcncategory':citem.getSubCnCategory()}
lst.append(dictM)
self.db.subcategoryall.insert(lst) def GetSubCategoryUrl(self):
categorys = self.db.subcategoryall.find({'iscrawl': 0}, {'_id': 0, 'url': 1, 'index': 1, 'category':1,'subcategory': 1, 'cncategory':1,'subcncategory': 1}).sort(
'index', ASCENDING)
return categorys def SaveSubCategoryData(self, subcategory_list):
lst = []
for hyobj in subcategory_list:
count = self.db.subcategorydata.find(
{'netname': hyobj.getNetName(), 'domainname': hyobj.getDomainName(), 'category': hyobj.getCategory()}).count()
if count == 0:
dictM = {'netname': hyobj.getNetName(),
'domainname': hyobj.getDomainName(),
'netrank': hyobj.getNetRank(),
'netscore': hyobj.getNetScore(),
'alexarank': hyobj.getAlexaRank(),
'antichaincount': hyobj.getAntichainCount(),
'neturl': hyobj.getNetUrl(),
'netdescription': hyobj.getNetDescription(),
'category': hyobj.getCategory(),
'cncategory': hyobj.getCnCategory()
}
lst.append(dictM)
# 批量插入
if len(lst) > 0:
self.db.subcategorydata.insert(lst) def SetSubCategoryState(self, url):
self.db.subcategoryall.update({'url': url}, {'$set': {'iscrawl': 1}}) def GetSubCategoryData(self):
# [(‘age‘,pymongo.DESCENDING),('name',pymongo.ASCENDING)]
rows = self.db.subcategorydata.find({}, {'_id': 0}).sort([('category',ASCENDING),('netrank',ASCENDING)])
return rows
# d = mongoDbBase() # urls = []
# urls.append('abc')
# # d.SaveUrls(urls)
# d.SetUrlCrawlState(urls)
# coding=utf-8
import os from selenium import webdriver
# from datetime import datetime,timedelta
# import selenium.webdriver.support.ui as ui
from selenium.common.exceptions import TimeoutException
import time
from pyquery import PyQuery as pq
import re
import mongoDB
from categoryItem import categoryItem
# import urllib2
import hyData
class category: def __init__(self):
#通过配置文件获取IEDriverServer.exe路径
# IEDriverServer ='C:\Program Files\Internet Explorer\IEDriverServer.exe'
# self.driver = webdriver.Ie(IEDriverServer)
# self.driver.maximize_window()
self.driver = webdriver.PhantomJS(service_args=['--load-images=false'])
self.driver.set_page_load_timeout(10)
self.driver.maximize_window()
self.db = mongoDB.mongoDbBase() def WriteLog(self, message,subdir,dir):
fileName = os.path.join(os.getcwd(), 'hangye/'+ subdir + '/' + dir + '.txt')
fileName = unicode(fileName,'utf8')
with open(fileName, 'a') as f:
f.write(message) # 根据链接获取该链接下的分类及其链接
def getCategoryAndUrls(self,url):
category_list = []
try:
self.driver.get(url)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
Elements = doc('div[class="HeadFilter clearfix"]').find('a') for element in Elements.items():
cncategory = element.text().encode('utf8')
categoryUrl = 'http://top.chinaz.com/hangye/' + element.attr('href')
ts = categoryUrl.split('_')
category = ts[len(ts) - 1].replace('.html', '')
message = '{0},{1},{2}'.format(category,cncategory,categoryUrl)
category_list.append(message)
except TimeoutException,e:
pass
return category_list # 根据分类的链接,获取该分类总页数 # 获取当前链接的总页数
def getPageCount(self, url):
pageCount = 0
try:
pattern = re.compile("\d+")
self.driver.get(url)
time.sleep(1)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
Elements = doc('div[class="ListPageWrap"]').find('a') for element in Elements.items():
temp = element.text().encode('utf8')
if temp != '<' and temp != '>':
ts = pattern.findall(temp)
if ts and len(ts) == 1:
count = int(ts[0])
if count > pageCount:
pageCount = count
except TimeoutException, e:
pass
return pageCount # 更新所有分类的总页数
def saveCategoryPageCount(self):
urls = self.db.GetCategory()
for u in urls:
url = u['url']
category = u['category']
pageCount = self.getPageCount(url)
if pageCount > 0:
self.db.UpdateCategoryPageCount(category, pageCount) # 保存分类的所有url
def saveCategoryAllUrls(self):
categorys = self.db.GetCategories()
index = 0
categoryItem_list = []
for c in categorys:
url = c['url']
category = c['category']
cncategory = c['cncategory']
count = c['count'] + 1
item = categoryItem()
item.setCategroy(category)
item.setCnCategroy(cncategory)
item.setUrl(url)
item.setUrlIndex(index)
categoryItem_list.append(item)
index += 1
for i in range(2, count):
url1 = url.replace('.html', '_' + str(i) + '.html')
it = categoryItem()
it.setCategroy(category)
it.setCnCategroy(cncategory)
it.setUrl(url1)
it.setUrlIndex(index)
categoryItem_list.append(it)
index += 1 self.db.SaveCategoryUrls(categoryItem_list) # 保存分类信息
def saveCategory(self):
# url = 'http://top.chinaz.com/hangye/index.html'
# # 1、首先根据初始链接,获取下面的所有分类,分类拼音,及分类对应的链接并保存数据库
# category_list = self.getCategoryAndUrls(url)
# for cs in category_list:
# category = cs.split(',')[0]
# cncategory = cs.split(',')[1]
# categoryUrl = cs.split(',')[2]
# self.db.SaveCategory(category, cncategory, categoryUrl)
# 2、更新所有分类中每种分类的总页数
# self.saveCategoryPageCount()
# 3、最后根据分类的总页数,保存分类的信息及链接
self.saveCategoryAllUrls()
self.driver.close()
self.driver.quit() # 根据url抓取分类链接
def catchCategoryByUrl(self,url,category,cncategory):
categroy_list = []
try:
self.driver.get(url)
time.sleep(2)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
# Elements = doc("div[@id='text_box_0']/dl/dd")
Elements = doc('li[class^="clearfix"]') # for element in Elements:
for element in Elements.items():
hyobj = hyData.hyData()
# column1Element = element.find('div[@class="text"]/h3/a')
# 网站名称,域名,网址
# netElement = element.find_element_by_xpath("//div[@class='CentTxt']/h3/a")
netElement = element.find('div[class="CentTxt"]').find('h3').find('a')
# netName = nextElement.get_attribute('title').encode('utf8')
netName = netElement.attr('title').encode('utf8').replace('\n', '').replace(',', ',') netUrl = 'http://top.chinaz.com' + netElement.attr('href').encode('utf8') # domainName = element.find_element_by_xpath('//div[class="CentTxt"]/h3/span').text.encode('utf8')
domainName = element.find('div[class="CentTxt"]').find('h3').find('span').text().encode('utf8') # Alexa周排名,反链数,网站描述
netinfo = element.find('div[class="RtCPart clearfix"]').text().encode('utf8')
pattern = re.compile("\d+")
ts = pattern.findall(netinfo)
alexaOrder = ''
antichainCount = ''
if ts and len(ts) == 2:
alexaOrder = ts[0]
antichainCount = ts[1] netDescription = element.find('p[class="RtCInfo"]').text().encode('utf8')
netDescription = netDescription.replace('网站简介:', '').replace(',', ',').replace('\n', '') # 排名,得分
netOrder = element.find('div[class="RtCRateCent"]').find('strong').text().encode('utf8')
netScore = element.find('div[class="RtCRateCent"]').find('span').text().encode('utf8')
netScore = netScore.replace('得分:', '') hyobj.setNetName(netName)
hyobj.setDomainName(domainName)
hyobj.setNetRank(int(netOrder))
hyobj.setNetScore(netScore)
hyobj.setAlexaRank(alexaOrder)
hyobj.setAntichainCount(antichainCount)
hyobj.setNetUrl(netUrl)
hyobj.setNetDescription(netDescription)
hyobj.setCategory(category)
hyobj.setCnCategory(cncategory)
categroy_list.append(hyobj)
except TimeoutException, e:
print 'timeout url: ' + url
return categroy_list # 抓取分类数据
def catchCategory(self):
urls = self.db.GetCategoryUrl()
lst = []
for u in urls:
url = u['url']
category = u['category'].encode('utf8')
cncategory = u['cncategory'].encode('utf8')
lst.append('{0},{1},{2}'.format(url, category, cncategory))
urls.close() for u in lst:
url = u.split(',')[0]
category = u.split(',')[1]
cncategory = u.split(',')[2]
category_list = self.catchCategoryByUrl(url, category, cncategory)
self.db.SaveCategoryData(category_list)
self.db.SetCategoryState(url)
print url self.driver.close()
self.driver.quit() # 导出分类数据
def exportCategory(self):
dataRows = self.db.GetCategoryData()
self.exportData(dataRows, 'category') # 更新所有子分类的总页数
def saveSubCategoryPageCount(self):
urls = self.db.GetSubCategory()
index = 1
for u in urls:
url = u['url']
pageCount = self.getPageCount(url)
if pageCount > 0:
self.db.UpdateSubCategoryPageCount(url, pageCount)
print index
index+=1 # 保存子分类所有url
def saveSubCategoryAllUrls(self):
categorys = self.db.GetSubCategories()
index = 0
categoryItem_list = []
for c in categorys:
url = c['url']
category = c['category']
cncategory = c['cncategory']
subcategory = c['subcategory']
subcncategory = c['subcncategory']
count = c['count'] + 1
item = categoryItem()
item.setCategroy(category)
item.setCnCategroy(cncategory)
item.setSubCategroy(subcategory)
item.setSubCnCategory(subcncategory)
item.setUrl(url)
item.setUrlIndex(index)
categoryItem_list.append(item)
index += 1
for i in range(2, count):
url1 = url.replace('.html', '_' + str(i) + '.html')
it = categoryItem()
it.setCategroy(category)
it.setCnCategroy(cncategory)
it.setSubCategroy(subcategory)
it.setSubCnCategory(subcncategory)
it.setUrl(url1)
it.setUrlIndex(index)
categoryItem_list.append(it)
index += 1 self.db.SaveSubCategoryUrls(categoryItem_list)
# 保存子分类信息 # 保存子分类数据
def saveSubCategory(self):
# cate = self.db.GetCategory()
# subcategory_list = []
# # 1、首先根据初始链接,获取下面的所有子分类,子分类拼音,及子分类对应的链接并保存数据库
# for u in cate:
# url = u['url']
# category = u['category'].encode('utf8')
# cncategory =u['cncategory'].encode('utf8')
# category_list =self.getCategoryAndUrls(url)
# for subcategory in category_list:
# temp = '{0},{1},{2}'.format(category,cncategory,subcategory)
# subcategory_list.append(temp)
# self.db.SaveSubCategory(subcategory_list) # # 2、更新所有子分类中每种分类的总页数
self.saveSubCategoryPageCount() # 3、最后根据子分类的总页数,保存子分类的信息及链接
self.saveSubCategoryAllUrls()
self.driver.close()
self.driver.quit() # 抓取子分类数据 # 抓取子分类数据
def catchSubCategory(self):
urls = self.db.GetSubCategoryUrl()
lst = []
for u in urls:
url = u['url']
category = u['category'].encode('utf8') + '_' + u['subcategory'].encode('utf8')
cncategory = u['cncategory'].encode('utf8') + '_' + u['subcncategory'].encode('utf8')
lst.append('{0},{1},{2}'.format(url,category,cncategory))
urls.close()
# pymongo.errors.CursorNotFound: Cursor not found, cursor id: 82792803897
for u in lst:
url = u.split(',')[0]
category = u.split(',')[1]
cncategory = u.split(',')[2]
category_list = self.catchCategoryByUrl(url, category, cncategory)
self.db.SaveSubCategoryData(category_list)
self.db.SetSubCategoryState(url)
print (url)
self.driver.close()
self.driver.quit() def exportData(self,dataRows,subdir):
count = 0
message = ''
tempcategory = ''
cncategory = ''
for dataRow in dataRows:
netname = dataRow['netname'].encode('utf8')
domainname = dataRow['domainname'].encode('utf8')
netrank = dataRow['netrank'] netscore = dataRow['netscore'].encode('utf8')
alexarank = dataRow['alexarank'].encode('utf8')
antichaincount = dataRow['antichaincount'].encode('utf8') neturl = dataRow['neturl'].encode('utf8')
netdescription = dataRow['netdescription'].encode('utf8')
# category = dataRow['category'].encode('utf8')
cncategory = dataRow['cncategory'].encode('utf8')
mess = '\n{0},{1},{2},{3},{4},{5},{6},{7},{8}'.format(netname, domainname,
netrank,
netscore, alexarank,
antichaincount, neturl,
netdescription, cncategory)
if tempcategory != cncategory: # 网站名称,网站域名,排名,得分,alexa排名,反链数,网站简介,网站类型
if len(message) > 0:
self.WriteLog(message,subdir, tempcategory)
message = mess
tempcategory = cncategory
else:
message += mess
# date = time.strftime('%Y-%m-%d')
count += 1
# print count
if len(message) > 0:
self.WriteLog(message,subdir, tempcategory)
# 导出子分类数据
def exportSubCategory(self):
dataRows = self.db.GetSubCategoryData()
self.exportData(dataRows,'subcategory') obj = category()
# obj.saveCategory()
# obj.catchCategory()
obj.exportCategory()
# obj.saveSubCategory()
# obj.catchSubCategory()
# obj.exportSubCategory()
# coding=utf-8
class hyData:
def __init__(self):
pass # 网站名称
def setNetName(self,netName):
self.NetName = netName def getNetName(self):
return self.NetName #网站域名
def setDomainName(self,domainName):
self.DomainName = domainName def getDomainName(self):
return self.DomainName # 网站排名
def setNetRank(self, netRank):
self.NetRank= netRank def getNetRank(self):
return self.NetRank # 网站得分
def setNetScore(self, netScore):
self.NetScore = netScore def getNetScore(self):
return self.NetScore # 栏目名称netName, domainName, netOrder, netScore,
# alexaOrder, antichainCount, netUrl,
# netDescription
# Alexa排名
def setAlexaRank(self, alexaRank):
self.AlexaRank = alexaRank def getAlexaRank(self):
return self.AlexaRank #反链数
def setAntichainCount(self, antichainCount):
self.AntichainCount = antichainCount def getAntichainCount(self):
return self.AntichainCount # 网站链接
def setNetUrl(self, netUrl):
self.NetUrl = netUrl def getNetUrl(self):
return self.NetUrl #网站简介
def setNetDescription(self, netDescription):
self.NetDescription = netDescription def getNetDescription(self):
return self.NetDescription # 分类拼音
def setCategory(self, category):
self.Category = category def getCategory(self):
return self.Category # 分类中文
def setCnCategory(self, cnCategory):
self.CnCategory = cnCategory def getCnCategory(self):
return self.CnCategory def setPageIndex(self, pageIndex):
self.PageIndex = pageIndex def getPageIndex(self):
return self.PageIndex
# coding=utf-8
class categoryItem:
def __init__(self):
pass
# 分类拼音subcncategory
def setCategroy(self, categroy):
self.Categroy = categroy def getCategroy(self):
return self.Categroy # 分类中文名
def setCnCategroy(self, cnCategroy):
self.CnCategroy = cnCategroy def getCnCategroy(self):
return self.CnCategroy # 分类url
def setUrl(self, url):
self.Url = url def getUrl(self):
return self.Url # url序号
def setUrlIndex(self, urlIndex):
self.UrlIndex = urlIndex def getUrlIndex(self):
return self.UrlIndex # 子分类拼音
def setSubCategroy(self, subCategroy):
self.SubCategroy = subCategroy def getSubCategroy(self):
return self.SubCategroy # 子分类中文名
def setSubCnCategory(self, subCnCategory):
self.SubCnCategory = subCnCategory def getSubCnCategory(self):
return self.SubCnCategory
[Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息的更多相关文章
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一.介绍 本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息. 给定关键字:视频:融合:电视 二 ...
- [Python爬虫] 之二十三:Selenium +phantomjs 利用 pyquery抓取智能电视网数据
一.介绍 本例子用Selenium +phantomjs爬取智能电视网(http://news.znds.com/article/news/)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字 ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
- [Python爬虫] 之二十:Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据
一.介绍 本例子用Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据()的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯 ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一.介绍 本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息 二.网站信息 三.数据抓 ...
- [Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息
一.介绍 本例子用Selenium +phantomjs爬取智能电视网站(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取图片信息. 给定关键字:数字:融合:电视 ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
随机推荐
- WordPress主题设置插件,让你的站点有电脑、手机双主题
我们建站的时候总是会优先考虑自适应的主题,但是与之对应,免费的自适应主题都调用国外公共资源,访问速度不太理想.加上wordpress未经优化之前,本身也没有极高的访问效率.所以大家可以下载这款“主题设 ...
- Go语言基础单元测试示例
这个要熟悉原理,要能写.. 但现在..... 注意,没有main函数,以_test.go结尾,命令go test -v package main import ( "testing" ...
- 解决JPA懒加载典型的N+1问题-注解@NamedEntityGraph
因为在设计一个树形结构的实体中用到了多对一,一对多的映射关系,在加载其关联对象的时候,为了性能考虑,很自然的想到了懒加载. 也由此遇到了N+1的典型问题 : 通常1的这方,通过1条SQL查找得到1个对 ...
- Pandas分组运算(groupby)修炼
Pandas分组运算(groupby)修炼 Pandas的groupby()功能很强大,用好了可以方便的解决很多问题,在数据处理以及日常工作中经常能施展拳脚. 今天,我们一起来领略下groupby() ...
- 进入CentOS7紧急模式恢复root密码
第一步.重启CentOS7,在以下界面选择要编辑的内核(一般第一个),按e进入编辑界面 第二步.在编辑界面找到如下一行,将ro改为rw init=/sysroot/bin/sh.改完后<Ctrl ...
- Flask实战第64天:帖子加精和取消加精功能完成
帖子加精和取消加精是在cms后台来设置的 后台逻辑 首页个帖子加精设计个模型表,编辑apps.models.py class HighlightPostModel(db.Model): __table ...
- RabbitMQ (十二) 消息确认机制 - 发布者确认
消费者确认解决的问题是确认消息是否被消费者"成功消费". 它有个前提条件,那就是生产者发布的消息已经"成功"发送出去了. 因此还需要一个机制来告诉生产者,你发送 ...
- Express使用MongoDB常用操作
const MongoClient = require('mongodb').MongoClient const url = "mongodb://localhost:27017" ...
- Python开发基础-Day18继承派生、组合、接口和抽象类
类的继承与派生 经典类和新式类 在python3中,所有类默认继承object,但凡是继承了object类的子类,以及该子类的子类,都称为新式类(在python3中所有的类都是新式类) 没有继承obj ...
- 文本转化工具dos2unix
文本转化工具dos2unix 由于历史原因,各个平台使用的文本编码规范不同,导致了同一文本在不同平台中显示不同.例如,Windows和Linux的换行符号不同,会造成多行文本显示混乱.为了解决这个 ...