scrapy爬虫爬取小姐姐图片(不羞涩)
这个爬虫主要学习scrapy的item Pipeline
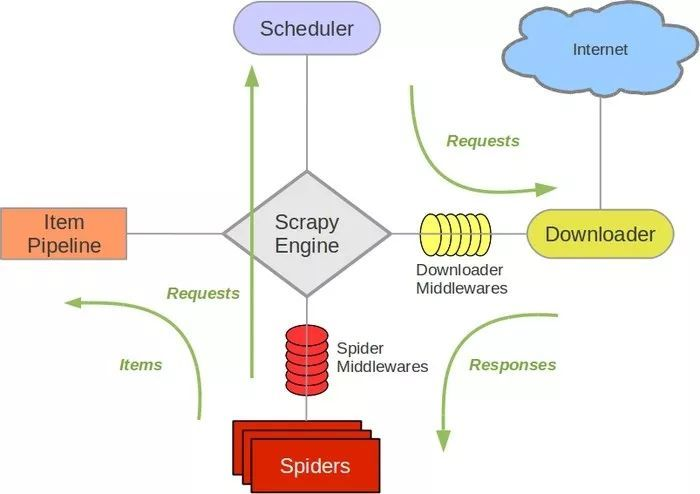
是时候搬出这张图了:
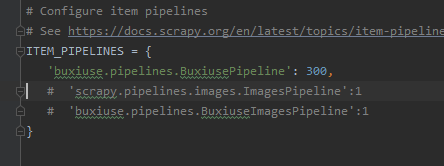
当我们要使用item Pipeline的时候,要现在settings里面取消这几行的注释
我们可以自定义Item Pipeline,只需要实现指定的方法,其中必须要实现的一个方法是: p
process_item(item,spider)
另外还有几个方法我们有时候会用到
open_spider(spider)
close_spider(spider)
from_crawler(cls,crawler)
在不羞涩的主页(https://www.buxiuse.com/)我们使用xpath进行分析可以得到每一张小姐姐图片的url,我们将每一页urls作为一个item对象返回,并且找到下一页的链接,持续爬取
class IndexSpider(scrapy.Spider):
name = 'index'
allowed_domains = ['buxiuse.com']
start_urls = ['https://www.buxiuse.com/?page=1']
base_domain="https://www.buxiuse.com" def parse(self, response):
image_urls=response.xpath('//ul[@class="thumbnails"]/li//img/@src').getall()
next_url=response.xpath('//li[@class="next next_page"]/a/@href').get()
item=BuxiuseItem(image_urls=image_urls)
yield item
if not next_url:
return
else:
yield scrapy.Request(self.base_domain+next_url)
对于yield的item对象,因为只返回了一个urls,所以我们在items进行设置
class BuxiuseItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls=scrapy.Field()
这样在刚才的index文件里面,才可以新建BuxiuseItem对象,
item=BuxiuseItem(image_urls=image_urls)
当然要先在index导入BuxiuseItem这个类
接着在pipeline里面我们处理接收到的Item和下载图片
我们先创建一个image的文件夹储存爬取到的图片,使用os.mkdir(self.path)
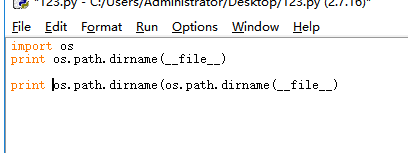
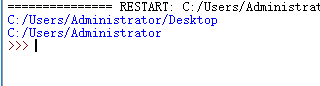
这个self.path由我们自己设定,这里学到了一个知识点:os.path.dirname(__file__)可以显示当前文件所在的位置
我们先输出一下
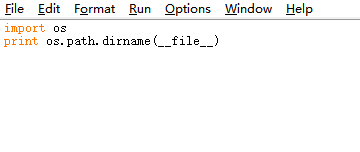
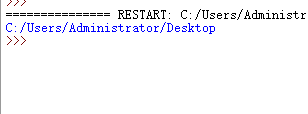
使用os.path.dirname(os.path.dirname(__file__))可以返回到上一级目录位置
我们使用这个方法控制储存的目录,如果是其他比较远的位置就使用绝对路径吧。
因为我是python2的环境,使用
urllib.urlretrieve(link,os.path.join(self.path,image_name))
将链接上的图片以指定的文件名保存在指定位置上
所以pipeline里面的代码就是
import os
import urllib
from scrapy.pipelines.images import ImagesPipeline
import settings
i=1
class BuxiusePipeline(object):
def __init__(self):
self.path=os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
if not os.path.exists(self.path):
os.mkdir(self.path) def process_item(self, item, spider):
global i
link_list=item['image_urls']
for link in link_list:
print i
image_name=str(i)+".jpg"
urllib.urlretrieve(link,os.path.join(self.path,image_name))
i=i+1
return item
输出i是为了让我能看到脚本还在正常下载,免得被网站ban掉了还不知道。
运行一下看看效果:
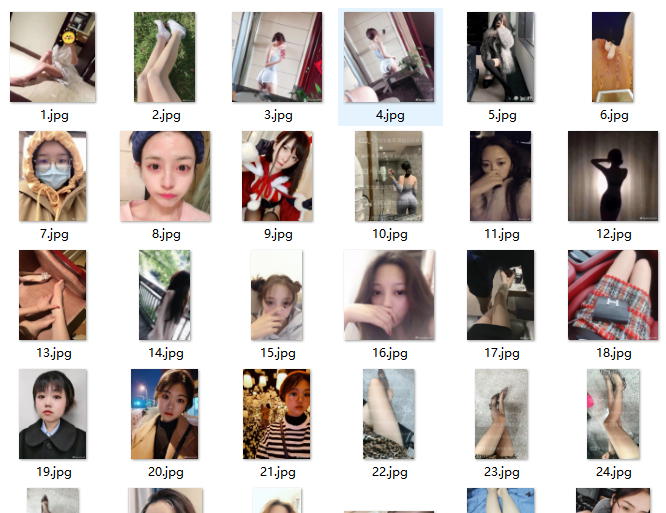
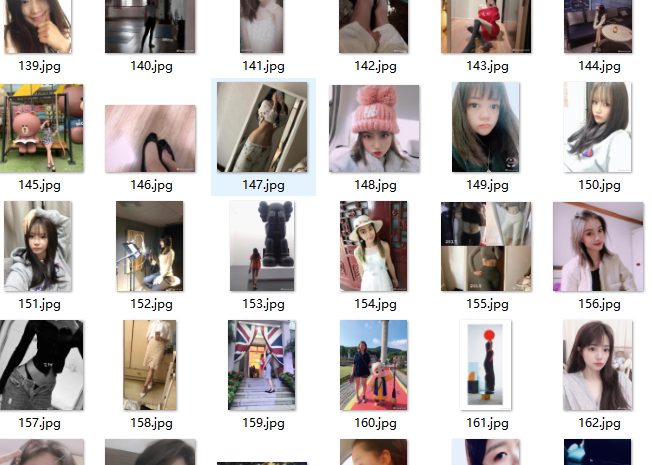
可以看到小姐姐的图片已经被下载下来了,并且按照i的编号整齐排列,完事。
github代码:
https://github.com/Cl0udG0d/scrapy_demo/tree/master/buxiuse
scrapy爬虫爬取小姐姐图片(不羞涩)的更多相关文章
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- <scrapy爬虫>爬取校花信息及图片
1.创建scrapy项目 dos窗口输入: scrapy startproject xiaohuar cd xiaohuar 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # ...
- python爬虫——爬取NUS-WIDE数据库图片
实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需 ...
- <scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)
1.创建scrapy项目 dos窗口输入: scrapy startproject images360 cd images360 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) ...
- <scrapy爬虫>爬取猫眼电影top100详细信息
1.创建scrapy项目 dos窗口输入: scrapy startproject maoyan cd maoyan 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # -*- ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- <scrapy爬虫>爬取quotes.toscrape.com
1.创建scrapy项目 dos窗口输入: scrapy startproject quote cd quote 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) import ...
- <scrapy爬虫>爬取腾讯社招信息
1.创建scrapy项目 dos窗口输入: scrapy startproject tencent cd tencent 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # - ...
随机推荐
- C++ 数据结构 3:树和二叉树
1 树 1.1 定义 由一个或多个(n ≥ 0)结点组成的有限集合 T,有且仅有一个结点称为根(root),当 n > 1 时,其余的结点分为 m (m ≥ 0)个互不相交的有限集合T1,T2, ...
- 《我想进大厂》之Java基础夺命连环16问
说好了面试系列已经完结了,结果发现还是真香,嗯,以为我发现我的Java基础都没写,所以这个就算作续集了,续集第一篇请各位收好. 说说进程和线程的区别? 进程是程序的一次执行,是系统进行资源分配和调度的 ...
- 17flask分页
一,flask_sqlachemy的使用 如果想要展示出来的页面是分页显示,则首先需要知道每页应该分多少个条目,然后通过数据库去查找对应的条数,同时也需要和分页所需的"paginate&qu ...
- nginx&http 第三章 ngx http 框架处理流程
1. nginx 连接结构 ngx_connection_t 这个连接表示是客户端主动发起的.Nginx服务器被动接受的TCP连接,我们可以简单称其为被动连接.同时,在有些请求的处理过程中,Nginx ...
- one-wallhaven 一个壁纸程序
one-wallhaven 一款基于 Electron 壁纸客户端 . gitee:https://gitee.com/ml13/wallhaven-electron github:https://g ...
- mysql中delete from t1 where id = 10加锁状况叙述
在Next_Key Lock算法中,不仅仅锁定住所找到的索引,而且还锁定住这些索引覆盖的范围.因此在这个范围内的插入都是不允许的.这样就避免了在这个范围内插入数据导致的幻读问题. delete fro ...
- mysql的索引、视图、存储过程(自我理解总结)
一.索引 索引在MySQL中也叫'键'或者'key',是存储引擎用于快速找到记录的一种数据结构.索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要,减少IO次数,加 ...
- 公司新来的小姐姐不懂java中的static关键字,这样给她描述不香吗?
前言 static关键字是摆在刚入行编程语言的小白们面前的一道难题,为什么要用static?使用它有什么好处?修饰方法和修饰变量有什么区别?本文将就java中static关键字的使用方法及注意事项进行 ...
- kakafka - 为CQRS而生fka - 为CQRS而生
前段时间跟一个朋友聊起kafka,flint,spark这些是不是某种分布式运算框架.我自认为的分布式运算框架最基础条件是能够把多个集群节点当作一个完整的系统,然后程序好像是在同一台机器的内存里运行一 ...
- api-hook,更轻量的接口测试工具
前言 在网站的开发过程中,接口联调和测试是至关重要的一环,其直接影响产品的核心价值,而目前也有许多技术方案和工具加持,让我们的开发测试工作更加便捷.接口作为数据传输的重要载体,数据格式和内容具有多样性 ...