[Java]使用HttpClient实现一个简单爬虫,抓取煎蛋妹子图
第一篇文章,就从一个简单爬虫开始吧。
这只虫子的功能很简单,抓取到”煎蛋网xxoo”网页(http://jandan.net/ooxx/page-1537),解析出其中的妹子图,保存至本地。
先放结果:

从程序来讲,分为三个步骤:
1、发起一个http请求,获取返回的response内容;
2、解析内容,分离出有效图片的url;
3、根据这些图片的url,生成图片保存至本地。
开始详细说明:
准备工作:HttpClient的Jar包,访问http://hc.apache.org/ 自行下载。
主程序内容:
public class SimpleSpider {
//起始页码
private static final int page = 1538;
public static void main(String[] args) {
//HttpClient 超时配置
RequestConfig globalConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD).setConnectionRequestTimeout(6000).setConnectTimeout(6000).build();
CloseableHttpClient httpClient = HttpClients.custom().setDefaultRequestConfig(globalConfig).build();
System.out.println("5秒后开始抓取煎蛋妹子图……");
for (int i = page; i > 0; i--) {
//创建一个GET请求
HttpGet httpGet = new HttpGet("http://jandan.net/ooxx/page-" + i);
httpGet.addHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.152 Safari/537.36");
httpGet.addHeader("Cookie","_gat=1; nsfw-click-load=off; gif-click-load=on; _ga=GA1.2.1861846600.1423061484");
try {
//不敢爬太快
Thread.sleep(5000);
//发送请求,并执行
CloseableHttpResponse response = httpClient.execute(httpGet);
InputStream in = response.getEntity().getContent();
String html = Utils.convertStreamToString(in);
//网页内容解析
new Thread(new JianDanHtmlParser(html, i)).start();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
HttpClient是一个非常强大的工具,属于apache下项目。如果只是创建一个默认的httpClient实例,代码很简单,官网手册上有详细说明。
可以看到在创建一个GET请求时,加入了请求头。第一个User-Agent代表所使用浏览器。有些网站需要明确了解用户所使用的浏览器,而有些不需要。个人猜测,部分网站根据用户使用浏览器不同显示不一样。这里的煎蛋网,就必须得加入请求头。第二个Cookie则代表了一些用户设置,可以没有。使用chrome的开发者工具就能清楚看到。如果是https加密后的,则需要特殊的抓包工具。
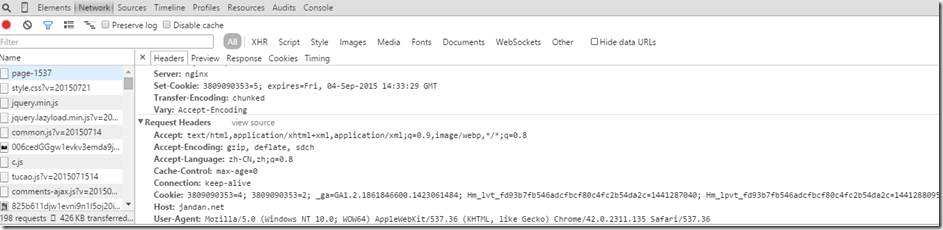
网页内容解析
public class JianDanHtmlParser implements Runnable {
private String html;
private int page;
public JianDanHtmlParser(String html,int page) {
this.html = html;
this.page = page;
}
@Override
public void run() {
System.out.println("==========第"+page+"页============");
List<String> list = new ArrayList<String>();
html = html.substring(html.indexOf("commentlist"));
String[] images = html.split("li>");
for (String image : images) {
String[] ss = image.split("br");
for (String s : ss) {
if (s.indexOf("<img src=") > 0) {
try{
int i = s.indexOf("<img src=\"") + "<img src=\"".length();
list.add(s.substring(i, s.indexOf("\"", i + 1)));
}catch (Exception e) {
System.out.println(s);
}
}
}
}
for(String imageUrl : list){
if(imageUrl.indexOf("sina")>0){
new Thread(new JianDanImageCreator(imageUrl,page)).start();
}
}
}
}
这段代码看起来凌乱,但实际上却特别简单。简单说便是,将response返回的html字符串解析,截取,找到真正需要的内容(图片url),存入到临时容器中。
生成图片类
public class JianDanImageCreator implements Runnable {
private static int count = 0;
private String imageUrl;
private int page;
//存储路径,自定义
private static final String basePath = "E:/jiandan";
public JianDanImageCreator(String imageUrl,int page) {
this.imageUrl = imageUrl;
this.page = page;
}
@Override
public void run() {
File dir = new File(basePath);
if(!dir.exists()){
dir.mkdirs();
System.out.println("图片存放于"+basePath+"目录下");
}
String imageName = imageUrl.substring(imageUrl.lastIndexOf("/")+1);
try {
File file = new File( basePath+"/"+page+"--"+imageName);
OutputStream os = new FileOutputStream(file);
//创建一个url对象
URL url = new URL(imageUrl);
InputStream is = url.openStream();
byte[] buff = new byte[1024];
while(true) {
int readed = is.read(buff);
if(readed == -1) {
break;
}
byte[] temp = new byte[readed];
System.arraycopy(buff, 0, temp, 0, readed);
//写入文件
os.write(temp);
}
System.out.println("第"+(count++)+"张妹子:"+file.getAbsolutePath());
is.close();
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
根据每个图片的src地址创建一个URL对象,再使用字节流,生成本地文件。
这个程序相对来说比较简单,纯属娱乐。如果能让那些不了解HttpClient的同学对这个库产生兴趣,则功德无量。
github地址:https://github.com/nbsa/SimpleSpider
PS:这个博客只提供抓取图片的方法,图片版权属于原网站及其网友。请大家尊重原网劳动成果,避免分发、传播图片内容。
[Java]使用HttpClient实现一个简单爬虫,抓取煎蛋妹子图的更多相关文章
- Golang分布式爬虫:抓取煎蛋文章|Redis/Mysql|56,961 篇文章
--- layout: post title: "Golang分布式爬虫:抓取煎蛋文章" date: 2017-04-15 author: hunterhug categories ...
- 爬虫技术 -- 进阶学习(七)简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 爬虫技术(四)-- 简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- Python3简单爬虫抓取网页图片
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到 ...
- python3爬虫爬取煎蛋网妹纸图片(上篇)
其实之前实现过这个功能,是使用selenium模拟浏览器页面点击来完成的,但是效率实际上相对来说较低.本次以解密参数来完成爬取的过程. 首先打开煎蛋网http://jandan.net/ooxx,查看 ...
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
- 用python来抓取“煎蛋网”上面的美女图片,尺度很大哦!哈哈
所用Python环境为:python 3.3.2 用到的库为:urllib.request re 废话不多说,先上代码: import urllib.request import re #获 ...
- python3爬虫爬取煎蛋网妹纸图片(下篇)2018.6.25有效
分析完了真实图片链接地址,下面要做的就是写代码去实现了.想直接看源代码的可以点击这里 大致思路是:获取一个页面的的html---->使用正则表达式提取出图片hash值并进行base64解码--- ...
随机推荐
- 9.JAVA之GUI编程列出指定目录内容
代码如下: /*列出指定目录内容*/ import java.awt.Button; import java.awt.FlowLayout; import java.awt.Frame; import ...
- 生成随机id对比
生成随机id 最近公司的项目游戏生成的随机不重复id,重复概率有点大, 代码如下: private static int id = 0; public static int serverID = 0; ...
- JavaScript 垃圾回收
在公司经常会听到大牛们讨论时说道内存泄露神马的,每每都惊羡不已,最近精力主要用在了Web 开发上,读了一下<JavaScript高级程序设计>(书名很唬人,实际作者写的特别好,由浅入深)了 ...
- Cesium原理篇:5最长的一帧之影像
如果把地球比做一个人,地形就相当于这个人的骨骼,而影像就相当于这个人的外表了.之前的几个系列,我们全面的介绍了Cesium的地形内容,详见: Cesium原理篇:1最长的一帧之渲染调度 Cesium原 ...
- 如何在SpringBoot中使用JSP ?但强烈不推荐,果断改Themeleaf吧
做WEB项目,一定都用过JSP这个大牌.Spring MVC里面也可以很方便的将JSP与一个View关联起来,使用还是非常方便的.当你从一个传统的Spring MVC项目转入一个Spring Boot ...
- Golang接口(interface)三个特性(译文)
The Laws of Reflection 原文地址 第一次翻译文章,请各路人士多多指教! 类型和接口 因为映射建设在类型的基础之上,首先我们对类型进行全新的介绍. go是一个静态性语言,每个变量都 ...
- O365(世纪互联)SharePoint 之调查列表简单介绍
前言 SharePoint中为了提供了很多开箱即用的应用程序,比如调查列表就是其中之一,同样,在O365版本里(国际版和世纪互联版本均可),也有这样的调查列表可以供我们使用,而使用起来非常方便和快速, ...
- iOS - ViewController的生命周期
iOS SDK中提供很多原生的ViewController,大大提高了我们的开发效率:那么下面我们就根据开发中我们常用的ViewController谈一谈它的生命周期: (一)按照结构和用法可以对iO ...
- Laravel大型项目系列教程(五)之文章和标签管理
一.前言 本节教程将大概完成文章和标签管理以及标签关联. 二.Let's go 1.文章管理 首先创建管理后台文章列表视图: $ php artisan generate:view admin.art ...
- 意外关机引起 IntelliJ IDEA 报 org.jdom.input.JDOMParseException 异常的,解决办法
详细错误如下: Error:Internal error: (org.jdom.input.JDOMParseException) Error on line 1: 前言中不允许有内容.org.jdo ...