[Python爬虫] 之十六:Selenium +phantomjs 利用 pyquery抓取一点咨询数据
本篇主要是利用 pyquery来定位抓取数据,而不用xpath,通过和xpath比较,pyquery效率要高。
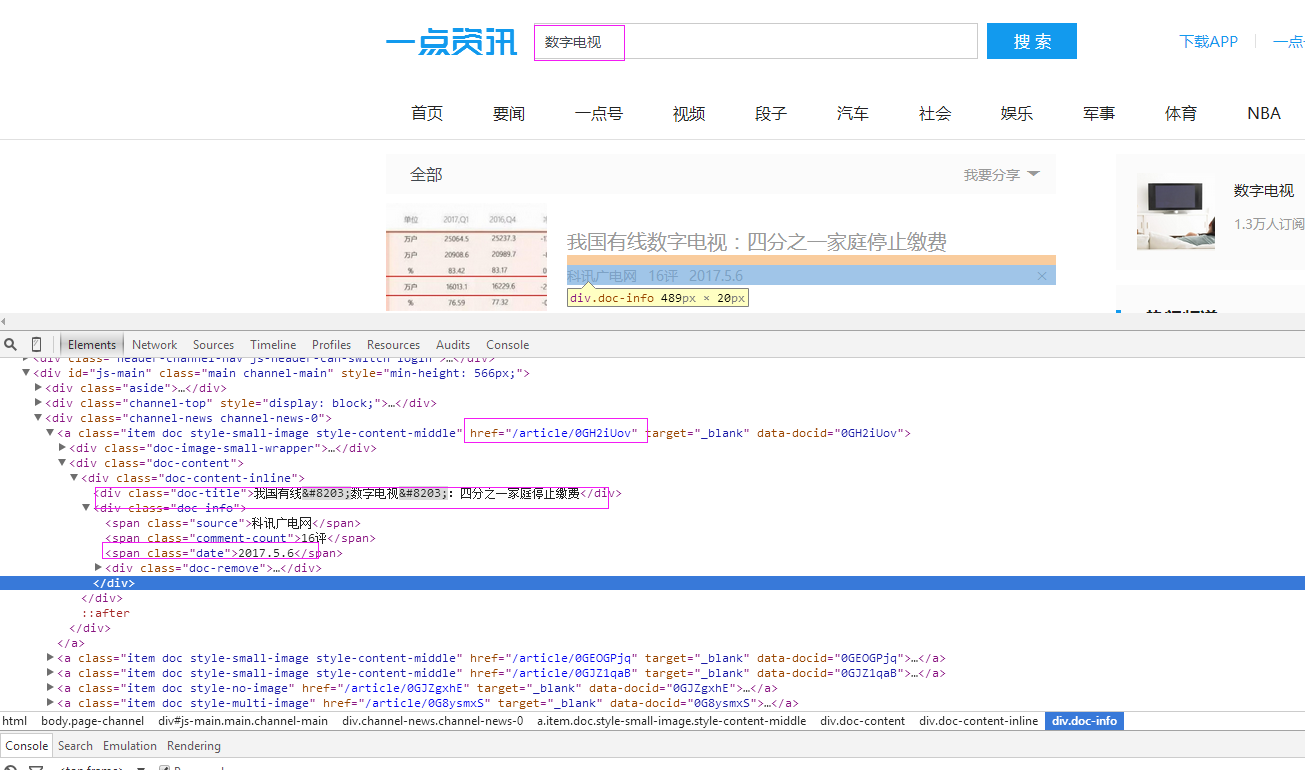
主要代码:
# coding=utf-8
import os
import re
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
from datetime import datetime
from selenium.webdriver.common.action_chains import ActionChains
import IniFile
from threading import Thread
from pyquery import PyQuery as pq
import LogFile
import mongoDB class yidianzixunSpider(object):
def __init__(self): logfile = os.path.join(os.path.dirname(os.getcwd()), time.strftime('%Y-%m-%d') + '.txt')
self.log = LogFile.LogFile(logfile)
configfile = os.path.join(os.path.dirname(os.getcwd()), 'setting.conf')
cf = IniFile.ConfigFile(configfile)
self.webSearchUrl_list = cf.GetValue("yidianzixun", "webSearchUrl").split(';')
self.keyword_list = cf.GetValue("section", "information_keywords").split(';')
self.db = mongoDB.mongoDbBase()
self.start_urls = []
for url in self.webSearchUrl_list:
self.start_urls.append(url) self.driver = webdriver.PhantomJS()
self.wait = ui.WebDriverWait(self.driver, 2)
self.driver.maximize_window() def scroll_foot(self):
'''
滚动条拉到底部
:return:
'''
js = ""
# 如何利用chrome驱动或phantomjs抓取
if self.driver.name == "chrome" or self.driver.name == 'phantomjs':
js = "var q=document.body.scrollTop=10000"
# 如何利用IE驱动抓取
elif self.driver.name == 'internet explorer':
js = "var q=document.documentElement.scrollTop=10000"
return self.driver.execute_script(js) def Comapre_to_days(self, leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 四种格式 '2小时前'; '2天前' ; '昨天' ;'2017.2.12 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
if strDateText.find('分钟前') > 0 or strDateText.find('刚刚') > -1:
return True, currentDate
elif strDateText.find('小时前') > 0:
datePattern = re.compile(r'\d{1,2}')
ch = int(time.strftime('%H')) # 当前小时数
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if int(strDate[0]) <= ch: # 只有小于当前小时数,才认为是今天
return True, currentDate
return False, '' def log_print(self, msg):
'''
# 日志函数
# :param msg: 日志信息
# :return:
# '''
print '%s: %s' % (time.strftime('%Y-%m-%d %H-%M-%S'), msg) def scrapy_date(self):
strsplit = '------------------------------------------------------------------------------------'
for link in self.start_urls: for i in range(5):
self.scroll_foot()
# time.sleep(1)
self.driver.get(link)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
infoList = [] self.log.WriteLog(strsplit)
self.log_print(strsplit)
Elements = doc('a[class^="item doc style-"]') # class属性内容以item doc style-开始的元素
for element in Elements.items():
date = element('span[class="date"]').text().encode('utf8').strip()
flag, strDate = self.date_isValid(date)
if flag:
title = element('div[class="doc-title"]').text().encode('utf8').strip() for keyword in self.keyword_list:
if title.find(keyword) > -1:
url = 'http://www.yidianzixun.com' + element.attr('href')
source = element('span[class="source"]').text().encode('utf8').strip() dictM = {'title': title, 'date': strDate,
'url': url, 'keyword': keyword, 'introduction': title, 'source': source}
infoList.append(dictM)
self.log.WriteLog('title:%s'%title)
self.log.WriteLog('url:%s' % url)
self.log.WriteLog('source:%s' % source)
self.log.WriteLog('kword:%s' % keyword) self.log_print('title:%s' % title)
self.log_print('url:%s' % url)
self.log_print('source:%s' % source)
self.log_print('kword:%s' % keyword)
break
if len(infoList)>0:
self.db.SaveInformations(infoList)
self.driver.close()
self.driver.quit() # obj = yidianzixunSpider()
# obj.scrapy_date()
[Python爬虫] 之十六:Selenium +phantomjs 利用 pyquery抓取一点咨询数据的更多相关文章
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之十七:Selenium +phantomjs 利用 pyquery抓取梅花网数据
一.介绍 本例子用Selenium +phantomjs爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字: ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之二十二:Selenium +phantomjs 利用 pyquery抓取界面网站数据
一.介绍 本例子用Selenium +phantomjs爬取界面(https://a.jiemian.com/index.php?m=search&a=index&type=news& ...
- [Python爬虫] 之二十三:Selenium +phantomjs 利用 pyquery抓取智能电视网数据
一.介绍 本例子用Selenium +phantomjs爬取智能电视网(http://news.znds.com/article/news/)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字 ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息
一.介绍 本例子用Selenium +phantomjs爬取智能电视网站(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取图片信息. 给定关键字:数字:融合:电视 ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- [Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一.介绍 本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息 二.网站信息 三.数据抓 ...
随机推荐
- Linux 基础——查看文件内容的命令
第四天,继续学习.今天看到一句话,"你以为你以为的就是你以为的吗?",这句话还是有点意思啊!!! 一.查看文件内容的命令 file dest:查看文件的类型.在Linux中,文件的 ...
- AC日记——Sagheer and Nubian Market codeforces 812c
C - Sagheer and Nubian Market 思路: 二分: 代码: #include <bits/stdc++.h> using namespace std; #defin ...
- section
@RenderSection("Header") @section Header { <div class="view"> @foreach ( ...
- .NET 简单的递归使用场景
什么是递归:自己调用自己,直到满足条件跳出 递归的缺点: 递归很耗内存,容易让机器挂掉 比如递归文件夹,当文件夹的层级有非常非常多的时候,就很容易挂掉,因为递归的时候把上层文件夹的上下文都保存在内存中 ...
- H5游戏开发:贪吃蛇
贪吃蛇的经典玩法有两种: 积分闯关 一吃到底 第一种是笔者小时候在掌上游戏机最先体验到的(不小心暴露了年龄),具体玩法是蛇吃完一定数量的食物后就通关,通关后速度会加快:第二种是诺基亚在1997年在其自 ...
- 一个通用的php正则表达式匹配或检测或提取特定字符类
在php开发时,日常不可或缺地会用到正则表达式,可每次都要重新写,有时忘记了某一函数还要翻查手册,所以,抽空写了一个关于日常所用到的正则表达式区配类,便于随便移置调用.(^_^有点偷懒). /*/ ...
- JqGrid的学习
http://blog.csdn.net/yangbobo1992/article/category/1227409
- hihoCoder #1871 : Heshen's Account Book-字符串暴力模拟 自闭(getline()函数) (ACM-ICPC Asia Beijing Regional Contest 2018 Reproduction B) 2018 ICPC 北京区域赛现场赛B
P2 : Heshen's Account Book Time Limit:1000ms Case Time Limit:1000ms Memory Limit:512MB Description H ...
- 转:智能模糊测试工具 Winafl 的使用与分析
本文为 椒图科技 授权嘶吼发布,如若转载,请注明来源于嘶吼: http://www.4hou.com/technology/2800.html 注意: 函数的偏移地址计算方式是以IDA中出现的Imag ...
- 洛谷P1908 逆序对 [权值线段树]
题目传送门 逆序对 题目描述 猫猫TOM和小老鼠JERRY最近又较量上了,但是毕竟都是成年人,他们已经不喜欢再玩那种你追我赶的游戏,现在他们喜欢玩统计.最近,TOM老猫查阅到一个人类称之为“逆序对”的 ...