<scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)
1.创建scrapy项目
dos窗口输入:
scrapy startproject images360
cd images360
2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义)
import scrapy class Images360Item(scrapy.Item):
# define the fields for your item here like:
#图片ID
image_id = scrapy.Field()
#链接
url = scrapy.Field()
#标题
title = scrapy.Field()
#缩略图
thumb = scrapy.Field()
3.创建爬虫文件
dos窗口输入:
scrapy genspider myspider images.so.com
4.编写myspider.py文件(接收响应,处理数据)
# -*- coding: utf-8 -*-
from urllib.parse import urlencode
import scrapy
from images360.items import Images360Item
import json class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['images.so.com']
urls = []
data = {'ch': 'beauty', 'listtype': 'new'}
base_url = 'https://image.so.com/zj?0'
for page in range(1,51):
data['sn'] = page * 30
params = urlencode(data)
url = base_url + params
urls.append(url)
print(urls)
start_urls = urls # ch: beauty
# sn: 120
# listtype: new
# temp: 1 def parse(self, response):
result = json.loads(response.text)
for each in result.get('list'):
item = Images360Item()
item['image_id'] = each.get('imageid')
item['url'] = each.get('qhimg_url')
item['title'] = each.get('group_title')
item['thumb'] = each.get('qhimg_thumb_url')
yield item
5.编写pipelines.py(存储数据)
import pymysql.cursors class Images360Pipeline(object):
def __init__(self):
self.connect = pymysql.connect(
host='localhost',
user='root',
password='',
database='quotes',
charset='utf8',
)
self.cursor = self.connect.cursor() def process_item(self, item, spider):
item = dict(item)
sql = 'insert into images360(image_id,url,title,thumb) values(%s,%s,%s,%s)'
self.cursor.execute(sql, (item['image_id'], item['url'], item['title'],item['thumb']))
self.connect.commit()
return item def close_spider(self, spider):
self.cursor.close()
self.connect.close()
6.编写settings.py(设置headers,pipelines等)
robox协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
headers
DEFAULT_REQUEST_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
pipelines
ITEM_PIPELINES = {
'quote.pipelines.Images360Pipeline': 300,
}
7.运行爬虫
dos窗口输入:
scrapy crawl myspider
运行结果
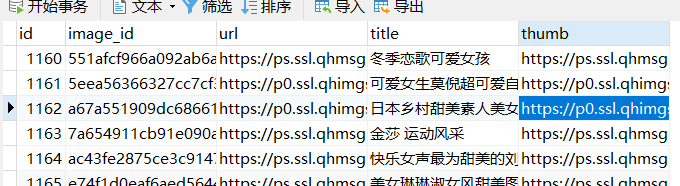
<scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)的更多相关文章
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- Scrapy框架学习(四)爬取360摄影美图
我们要爬取的网站为http://image.so.com/z?ch=photography,打开开发者工具,页面往下拉,观察到出现了如图所示Ajax请求, 其中list就是图片的详细信息,接着观察到每 ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- <scrapy爬虫>爬取猫眼电影top100详细信息
1.创建scrapy项目 dos窗口输入: scrapy startproject maoyan cd maoyan 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # -*- ...
- <scrapy爬虫>爬取quotes.toscrape.com
1.创建scrapy项目 dos窗口输入: scrapy startproject quote cd quote 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) import ...
- scrapy爬虫爬取小姐姐图片(不羞涩)
这个爬虫主要学习scrapy的item Pipeline 是时候搬出这张图了: 当我们要使用item Pipeline的时候,要现在settings里面取消这几行的注释 我们可以自定义Item Pip ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- <scrapy爬虫>爬取校花信息及图片
1.创建scrapy项目 dos窗口输入: scrapy startproject xiaohuar cd xiaohuar 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # ...
- <scrapy爬虫>爬取腾讯社招信息
1.创建scrapy项目 dos窗口输入: scrapy startproject tencent cd tencent 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # - ...
随机推荐
- bzoj1025题解
[题意分析] 定义一个等价类为满足如下条件的一个极大的集合Q:∀t∈Q,k∈N+,若tk∈全集R,都成立tk∈Q. 给定n,记[1,n]∩N上所有排列置换的全集为R.求对于所有的等价类Q,card({ ...
- 字符串hash+找模数——cf985F
19260817比自然溢出都要好使 /* 把原串变成用26个01串表示,第i个串对应的字符是i 然后进行字符串hash,s和t双射的条件是26个串的hash值排序后一一相等 */ #include&l ...
- 关于SecureCRT链接服务器出现乱码的问题
连接到服务器,选择上方的“选项”->“会话选项”->“外观”->右边的字符编码->utf-8
- delphi里为程序任务栏右键菜单添加自定义菜单
本文讲解的是为自身程序的任务栏右键菜单里添加自己定义的菜单的方法: delphi添加任务栏右键菜单 procedure TForm1.FormCreate(Sender: TObject); var ...
- MFC-按行读取TXT数据
TXT中数据格式如下: 1 23 4 0 4 10 …… 要实现的功能是:定义一个函数,每次调用时从TXT文档中读一个整数 ,赋值给变量.同时,文件位置向下移动一行,以便下次调用时读取下一行的数据. ...
- (转)python之函数介绍及使用
为什么要用函数? 1.减少代码量 2.保持一致性 3.易维护 一.函数的定义和使用 ? 1 2 3 4 5 6 def test(参数): ... 函数体 . ...
- 10.1 Nested vectored interrupt controller (NVIC) 嵌套矢量中断控制器
特点 60个可屏蔽中断通道(不包含16个Cortex™-M3的中断线): 16个可编程的优先等级(使用了4位中断优先级): 低延迟的异常和中断处理: 电源管理控制: 系统控制寄存器的实现: 1. 中断 ...
- USACO2005 City Skyline /// oj23401
题目大意: Input * Line 1: Two space separated integers: N and W * Lines 2..N+1: Two space separated inte ...
- js实现图片资源、blob、base64的各种场景转换
文件转babase64 function getImgToBase64(url,callback){//将图片转换为Base64 var canvas = document.createElement ...
- 2018-10-8-3分钟教你搭建-gitea-在-Centos-服务器
title author date CreateTime categories 3分钟教你搭建 gitea 在 Centos 服务器 lindexi 2018-10-08 09:54:39 +0800 ...