吴裕雄 python 机器学习——KNN分类KNeighborsClassifier模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import neighbors, datasets
from sklearn.model_selection import train_test_split def load_classification_data():
# 使用 scikit-learn 自带的手写识别数据集 Digit Dataset
digits=datasets.load_digits()
X_train=digits.data
y_train=digits.target
# 进行分层采样拆分,测试集大小占 1/4
return train_test_split(X_train, y_train,test_size=0.25,random_state=0,stratify=y_train) #KNN分类KNeighborsClassifier模型
def test_KNeighborsClassifier(*data):
X_train,X_test,y_train,y_test=data
clf=neighbors.KNeighborsClassifier()
clf.fit(X_train,y_train)
print("Training Score:%f"%clf.score(X_train,y_train))
print("Testing Score:%f"%clf.score(X_test,y_test)) # 获取分类模型的数据集
X_train,X_test,y_train,y_test=load_classification_data()
# 调用 test_KNeighborsClassifier
test_KNeighborsClassifier(X_train,X_test,y_train,y_test)
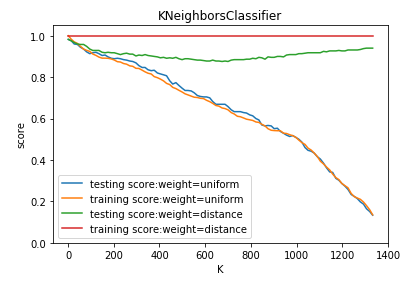
def test_KNeighborsClassifier_k_w(*data):
'''
测试 KNeighborsClassifier 中 n_neighbors 和 weights 参数的影响
'''
X_train,X_test,y_train,y_test=data
Ks=np.linspace(1,y_train.size,num=100,endpoint=False,dtype='int')
weights=['uniform','distance'] fig=plt.figure()
ax=fig.add_subplot(1,1,1)
### 绘制不同 weights 下, 预测得分随 n_neighbors 的曲线
for weight in weights:
training_scores=[]
testing_scores=[]
for K in Ks:
clf=neighbors.KNeighborsClassifier(weights=weight,n_neighbors=K)
clf.fit(X_train,y_train)
testing_scores.append(clf.score(X_test,y_test))
training_scores.append(clf.score(X_train,y_train))
ax.plot(Ks,testing_scores,label="testing score:weight=%s"%weight)
ax.plot(Ks,training_scores,label="training score:weight=%s"%weight)
ax.legend(loc='best')
ax.set_xlabel("K")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.set_title("KNeighborsClassifier")
plt.show() # 获取分类模型的数据集
X_train,X_test,y_train,y_test=load_classification_data()
# 调用 test_KNeighborsClassifier_k_w
test_KNeighborsClassifier_k_w(X_train,X_test,y_train,y_test)
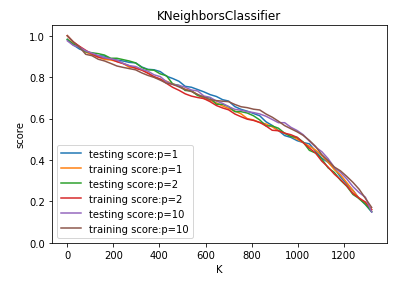
def test_KNeighborsClassifier_k_p(*data):
'''
测试 KNeighborsClassifier 中 n_neighbors 和 p 参数的影响
'''
X_train,X_test,y_train,y_test=data
Ks=np.linspace(1,y_train.size,endpoint=False,dtype='int')
Ps=[1,2,10] fig=plt.figure()
ax=fig.add_subplot(1,1,1)
### 绘制不同 p 下, 预测得分随 n_neighbors 的曲线
for P in Ps:
training_scores=[]
testing_scores=[]
for K in Ks:
clf=neighbors.KNeighborsClassifier(p=P,n_neighbors=K)
clf.fit(X_train,y_train)
testing_scores.append(clf.score(X_test,y_test))
training_scores.append(clf.score(X_train,y_train))
ax.plot(Ks,testing_scores,label="testing score:p=%d"%P)
ax.plot(Ks,training_scores,label="training score:p=%d"%P)
ax.legend(loc='best')
ax.set_xlabel("K")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.set_title("KNeighborsClassifier")
plt.show() # 获取分类模型的数据集
X_train,X_test,y_train,y_test=load_classification_data()
# 调用 test_KNeighborsClassifier_k_p
test_KNeighborsClassifier_k_p(X_train,X_test,y_train,y_test)
吴裕雄 python 机器学习——KNN分类KNeighborsClassifier模型的更多相关文章
- 吴裕雄 python 机器学习——KNN回归KNeighborsRegressor模型
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors, datasets from skle ...
- 吴裕雄 python 机器学习——半监督学习LabelSpreading模型
import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn import d ...
- 吴裕雄 python 机器学习——层次聚类AgglomerativeClustering模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——支持向量机非线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——支持向量机线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习-KNN(2)
import matplotlib import numpy as np import matplotlib.pyplot as plt from matplotlib.patches import ...
- 吴裕雄 python 机器学习-KNN算法(1)
import numpy as np import operator as op from os import listdir def classify0(inX, dataSet, labels, ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
随机推荐
- LaTeX技巧005:定制自己炫酷的章节样式实例
示例一: 实现代码: \usepackage[Lenny]{fncychap} 示例二: 实现代码: \usepackage[avantgarde]{quotchap} \renewcommand\c ...
- 温故知新的经典贪心题目:今年暑假不AC?
情景: “今年暑假不AC?” “是的.” “那你干什么呢?” “看世界杯呀,笨蛋!” “@#$%^&*%...” 确实如此,世界杯来了,球迷的节日也来了,估计很多ACMer也会抛开电脑,奔向电 ...
- linux虚拟机内网突然不通了
之前安装后 内网,外网测试通常的,今天有开发反应es服务不通了 后来到服务器查看了一下,es和同步服务都停了 重新启动,发现同步服务无法启动,网络问题 报错信息“Failed to initiali ...
- 牛客多校第七场H Pair 数位dp理解
Pair 题意 给出A B C,问x取值[1,A]和y取值[1,B]存在多少组pair<x,y>满足以下最小一种条件,\(x \& y >c\),\(x\) xor \(y& ...
- Redis 要学的
https://www.cnblogs.com/kismetv/p/8654978.html#t21 各个类型底层原理 慢查询 pipeline BitMaps 发布订阅 主从复制 psync psy ...
- python os 模块详解
os.sep:取代操作系统特定的路径分隔符 os.name:指示你正在使用的工作平台.比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'. os.getcwd:得 ...
- open函数 文件设置缓冲
# 注释 将文件写入硬件设备时,使用系统调用,这类I/O操作一般时间很长 # 为了减少I/O次数操作,文件通常使用缓冲区(有足够的数据才进行系统调用) # 文件缓冲行为分为: # 全缓冲: open函 ...
- tomcat集群搭建集成nginx负载均衡
软件基础+版本: 1.3台centos7系统,其中都已经配置完成了jdk环境,jdk的版本为 [root@node03 bin]# java -version java version "1 ...
- OpenCV的视频输入和相似度测量
#include <iostream> #include <string> #include <iomanip> // 控制浮动类型的打印精度 #include & ...
- jvm(n):JVM面试
Jvm内存结构,一般是面试官对Java虚拟机这块考察的第一问. Java虚拟机的内存结构一般可以从线程共有和线程私有两部分起头作答,然后再详细说明各自的部分,类似树状结构的作答,好处就是思路清晰,面试 ...