Coursera, Big Data 1, Introduction (week 3)
什么是分布式文件系统?为什么需要分布式文件系统?
如果文件系统可以管理用网络连接的很多个存储单元,叫分布式文件系统. 分布式文件系统提供了数据可扩展性,容错性,高并发. 这些是传统文件系统不具有的.
Hadoop getting started
为什么用Hadoop? Hadoop 的 4 个What 和 How.

Hadoop 的主要Goal:
1. 可扩展来增加 node
2. 容错,Node down 可以很容易recover
3. 可以读取各种格式的数据(structured, unstructured)
4. 把task 分配到不同node,具有并行计算能力
Hadoop 生态系统:
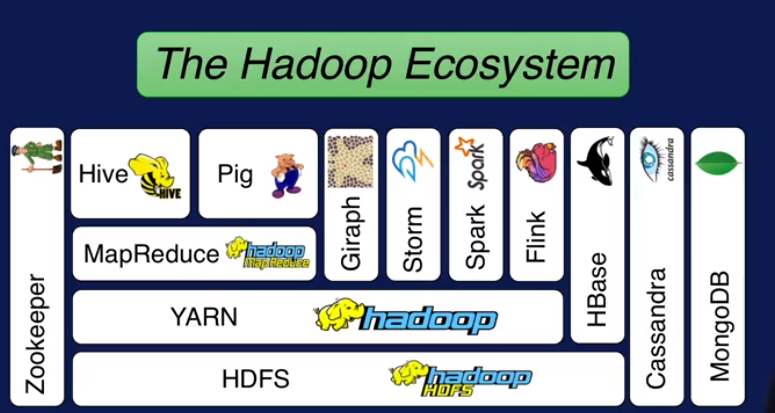
接下来先将整个Hadoop 生态系统,然后讲主要模块(HDFS分布式存储, YARN提供调度和资源管理, MapReduce并行计算) ,最后讲云计算(IaaS, PaaS, SaaS), 此外还有什么时候不适用 Hadoop.
Hadoop生态系统:
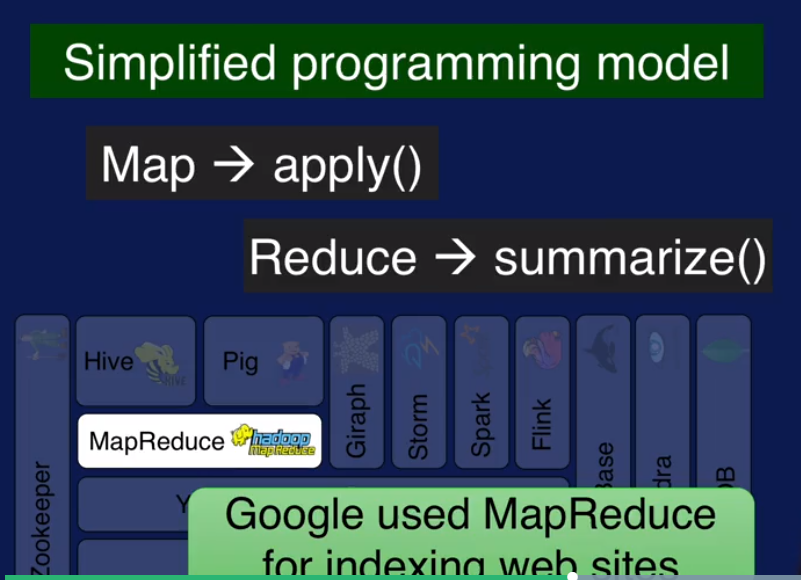
前面已经提到了HDFS 是管理分布式存储的, YARN 是负责调度和管理资源的,MapReduce 是做分布式计算的,用户只需要写两个函数就可以实现分布式计算了.
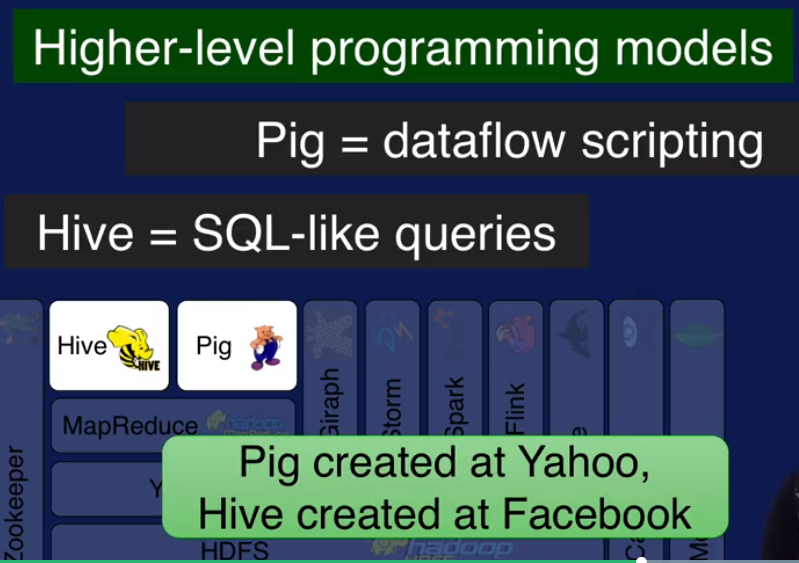
MapReduce 支持的数据model 有限,Hive 和 Pig 是分别针对 SQL-Like query 和 dataflow 类型数据的,可以理解为对MapReduce的扩展.
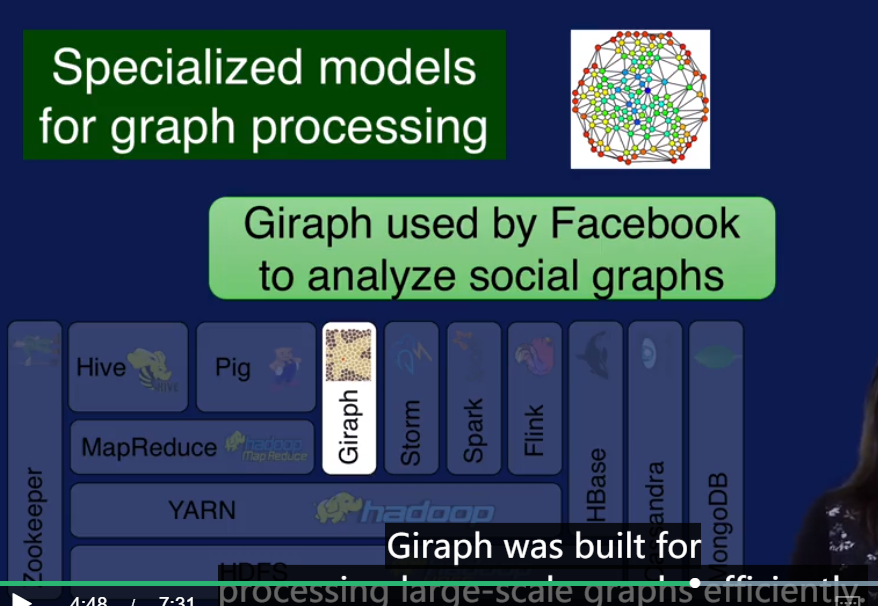
Giraph 用来处理大规模图表.
Storm, Spark, Flink 是内存处理大数据的技术.
Strom for streaming data analysis. Spark for in-memory data analysis.
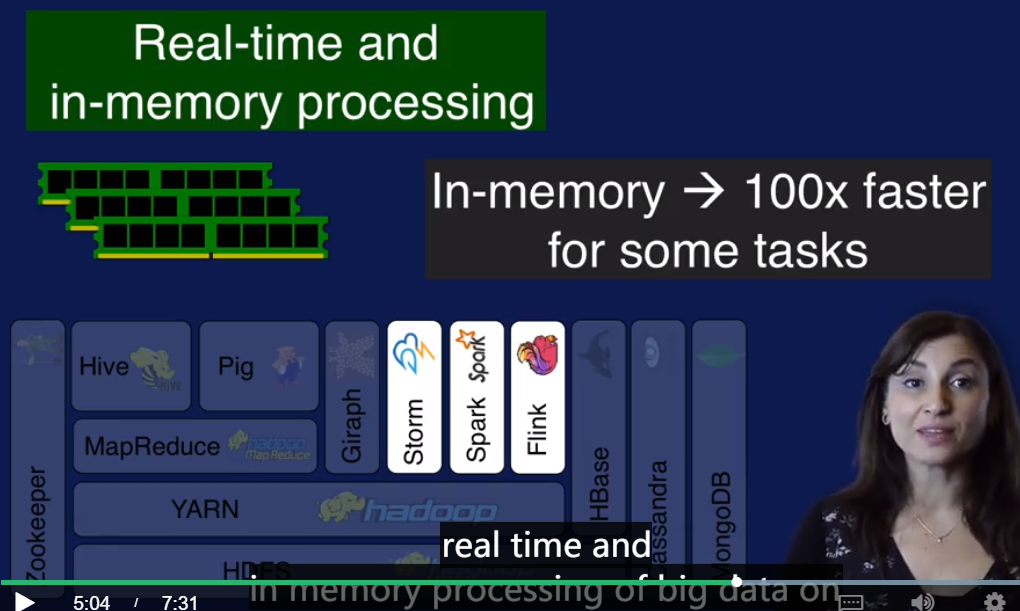
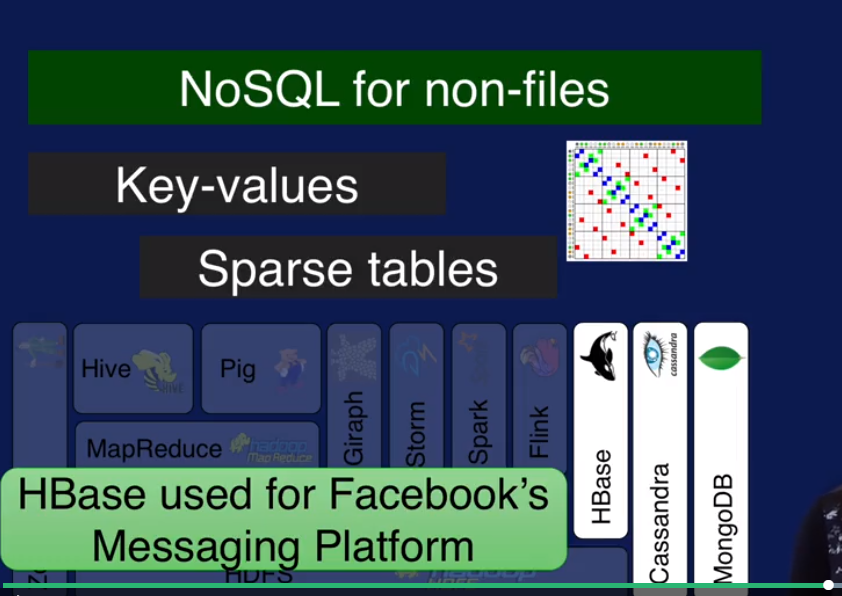
HBase, Cassandra, MongoDB 来处理一些不适合放在关系型数据库的数据,比如 key-value 数据,Sparse tables 数据. 这些都属于 NoSQL 数据库.
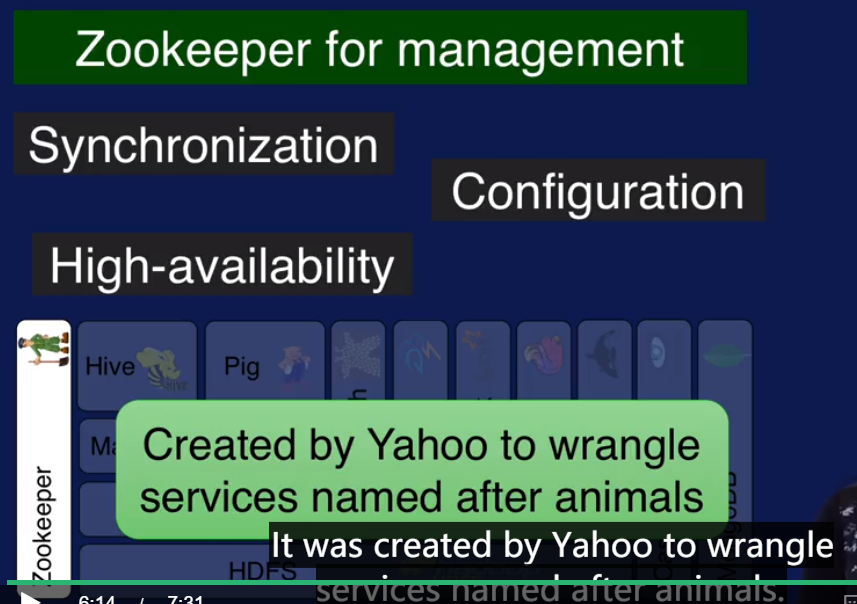
有了上面介绍的这么多模块,需要一个统一的集中管理工具来管理,就是Zookeeper.
这么多工具,如果自己来安排配置其实挺麻烦的,所有就有一些公司提供了集成的预装好的core工具集合,并对production env提供Support. 比如 Cloudera, MAPR, Hortonworks.

讲完了整个生态系统,接下来分别讲模块.
HDFS:
HDFS 怎么提供扩张性和可靠性? 以及它的两个关键模块 NameNode 和 DataNode.

HDFS 默认每一块数据放三份拷贝来提供可靠性. HDFS支持多种数据类型, 读和写时都需要提供数据类型.
HDFS由两种node 组成, Name Node (一般一个cluster就一个)和 Data Node (每个machine都是一个 data node).
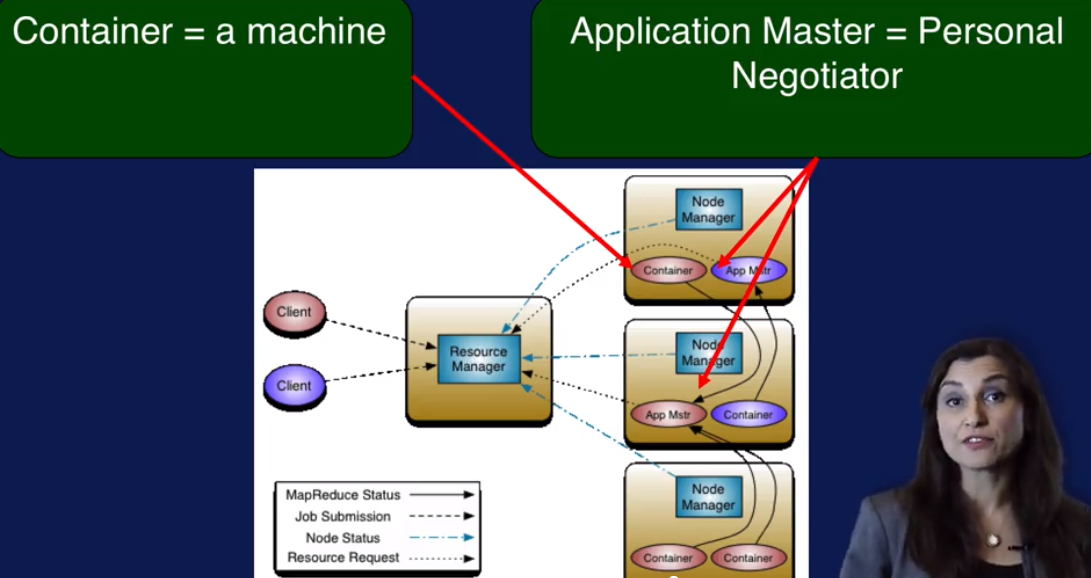
YARN: Resource manager for Hadoop
1. Resource manager and node manager
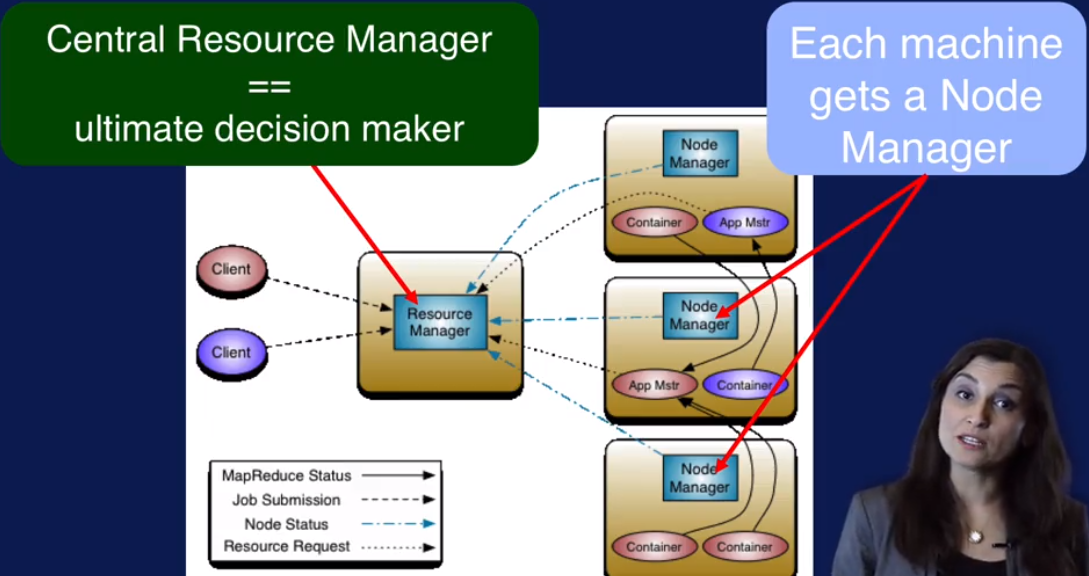
2. Appliacation Master 就像一个谈判人员, 从resource manager 协调资源,让node manager 来负责执行。
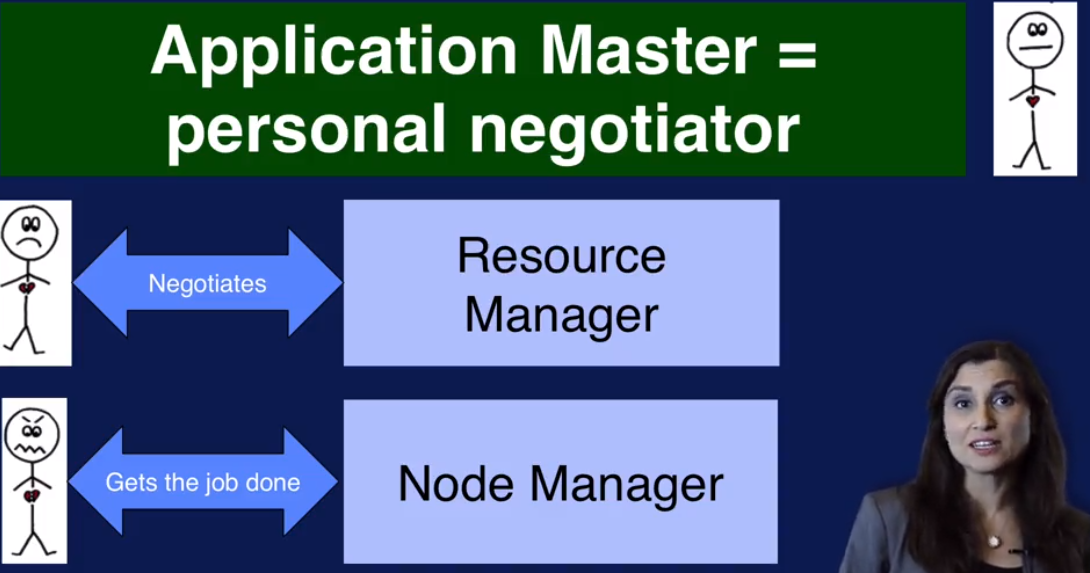
3. Container: 可以把它看做资源的抽象.
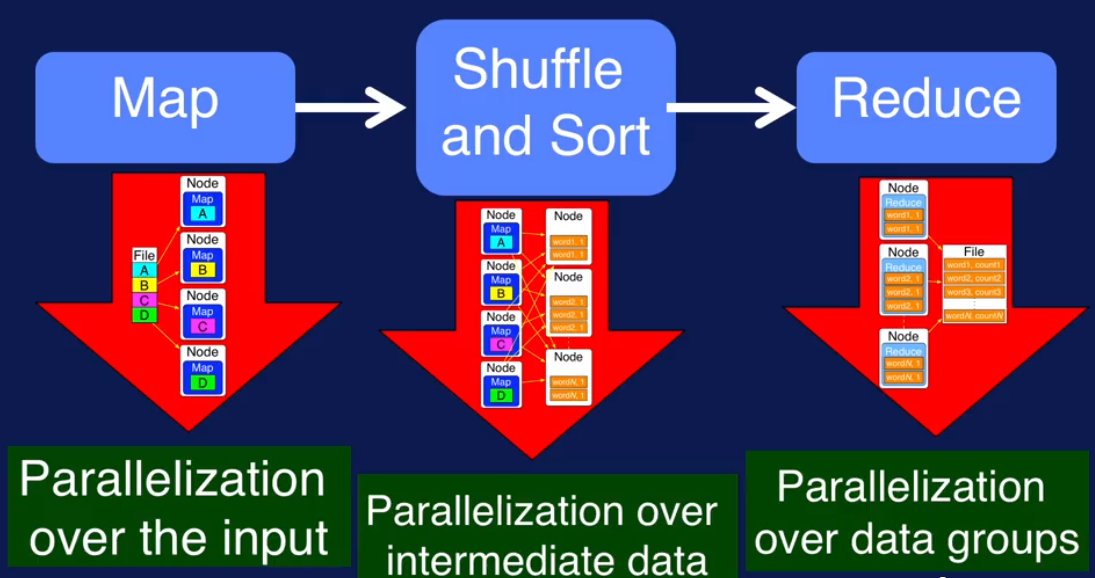
MapReduce:
计算分三步:Map -> Shuffle and Sort -> Reduce
下面图片用了WordCount 例子来显示这三个步骤



全局图
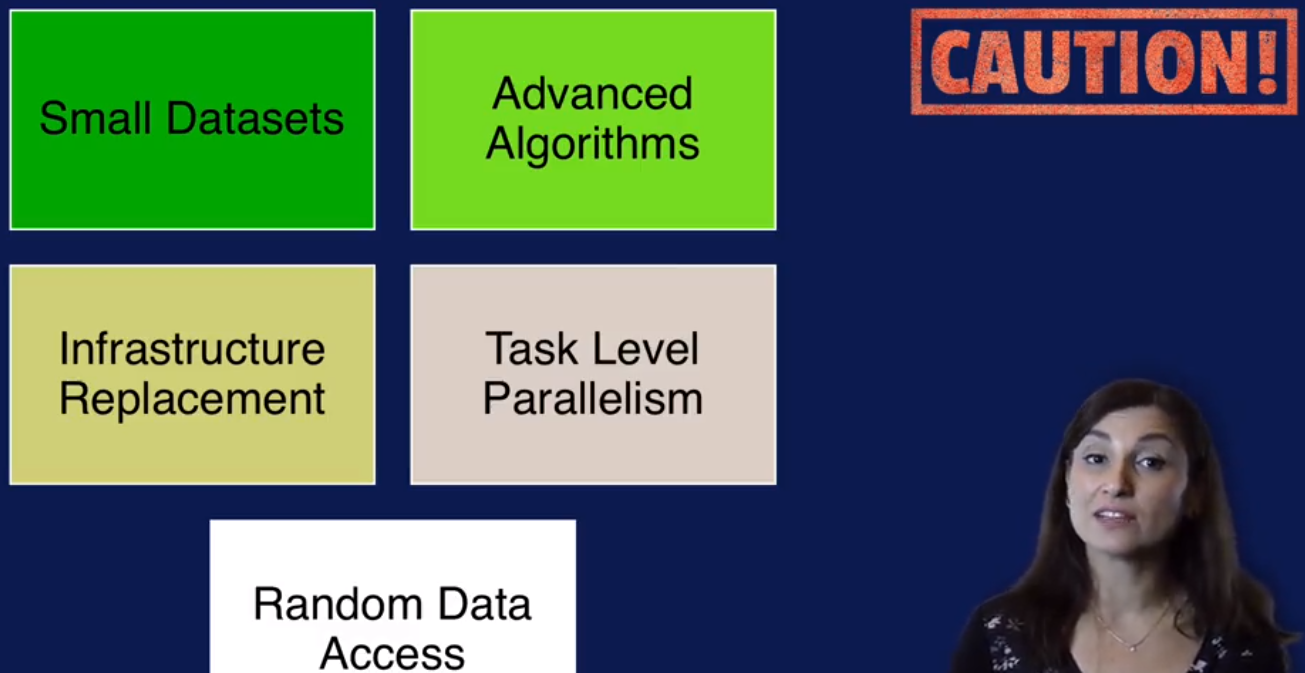
哪些情况不适合使用MapReduce: 因为每次都需要读取Input数据,所有Input数据不能随时变化,还有task 不能有先后依赖,还有MR 算完了才出结果也就不适合交互型的task.

什么情况下Hadoop使用或者不适用?
适用的场景包括了数据量比较大,数据格式多样等
不适用的场景:小数据量;一些数据之间有依赖的高级算法也不适用
云计算:
把基础架构交给云服务商,团队只需要关注应用.
IaaS: 比如 Amazon EC2, 阿里云
PaaS: Microsoft Azure, Google App Engine
SaaS: Dropbox
Value from Hadoop:
Coursera, Big Data 1, Introduction (week 3)的更多相关文章
- Coursera, Big Data 1, Introduction (week 1/2)
Status: week 2 done. Week 1, 主要讲了大数据的的来源 - 机器产生的数据,人产生的数据(比如社交软件上的update, 一般是unstructed data), 组织产生的 ...
- Building Applications with Force.com and VisualForce(Dev401)(十六):Data Management: Introduction to Upsert
Dev401-017:Data Management: Introduction to Upsert Module Objectives1.Define upsert.2.Define externa ...
- Coursera, Big Data 2, Modeling and Management Systems (week 1/2/3)
Introduction to data management 整个coures 2 是讲data management and storage 的,主要内容就是分布式文件系统,HDFS, Redis ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data KNime - GUI based Spark MLlib - inside Spark CRISP-DM Week 2, ...
- Coursera, Big Data 3, Integration and Processing (week 5)
Week 5, Big Data Analytics using Spark Programing in Spark Spark Core: Programming in Spark us ...
- Coursera, Big Data 3, Integration and Processing (week 4)
Week 4 Big Data Precessing Pipeline 上图可以generalize 成下图,也就是Big data pipeline some high level processi ...
- Coursera, Big Data 3, Integration and Processing (week 1/2/3)
This is the 3rd course in big data specification courses. Data model reivew 1, data model 的特点: Struc ...
- Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)
week4 streaming data format 下面讲 data lakes schema-on-read: 从数据源读取raw data 直接放到 data lake 里,然后再读到mode ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
随机推荐
- 构建高性能服务 Java高性能缓冲设计 vs Disruptor vs LinkedBlockingQueue
一个仅仅部署在4台服务器上的服务,每秒向Database写入数据超过100万行数据,每分钟产生超过1G的数据.而每台服务器(8核12G)上CPU占用不到100%,load不超过5.这是怎么做到呢?下面 ...
- ios自动打包-fastlane 安装、使用、更新和卸载
ios自动打包使用fastlane 1.首先安装xcode 首先检查是否已经安装 Xcode 命令行工具,fastlane 使用 xcodebuild 命令进行打包,运行 xcode-select - ...
- 多节点,多线程下发订单,使用zookeeper分布式锁机制保证订单正确接入oms系统
假设订单下发, 采用单机每分钟从订单OrderEntry接口表中抓100单, 接入订单oms系统中. 由于双十一期间, 订单量激增, 导致订单单机每分钟100单造成, 订单积压. 所以采用多节点多线程 ...
- 一人撸PaaS之“应用”
[什么是“应用”] 应用,如果按名词理解就是类似于可以使用的功能,比如一个App应用.事实上,一个应用包含了大量的交互功能以丰富我们的日常学习和生活. 我们这里的应用指的是一系列功能的集合,可以理解为 ...
- 关于表单元素的name及HTML中的id
这种在上高级WEB课时,老师为表单元素赋了name值,之后直接在JS中使用该值而不需要使用document.get...来获取了,例: <!DOCTYPE html> <html&g ...
- 通过JS获取URL链接带的参数
1 /** 2 * 获取URL参数的方法 3 */ 4 $.extend({ //以便于通过$引用该方法 5 getUrlVars : function() { //获取多个参数数组 6 var va ...
- redis cli命令
redis安装后,在src和/usr/local/bin下有几个以redis开头的可执行文件,称为redis shell,这些可执行文件可做很多事情. 可执行文件 作用 redis-server 启 ...
- 通过FactoryBean配置Bean
这是配置Bean的第三种方式,FactoryBean是Spring为我们提供的,我们先来看看源码: 第一个方法:public abstract T getObject() throws Excepti ...
- python之路6-迭代器、生成器、装饰器
1.迭代器&生成器 列表生成式 现在有个需求,列表[1,2,3,4,5,6,7,,8,9],要求把列表里的每个值加1,如何实现? 方法一: list = [1,2,3,4,5,6,7,8,9] ...
- Azure Machine Learning
About me In my spare time, I love learning new technologies and going to hackathons. Our hackathon p ...