Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)
week4
streaming data format
下面讲 data lakes

schema-on-read: 从数据源读取raw data 直接放到 data lake 里,然后再读到model里
schema-on-write: 传统模式,把raw data 经过处理后放到data warehouse里,此时已经是结构化的数据,然后直接load 出来

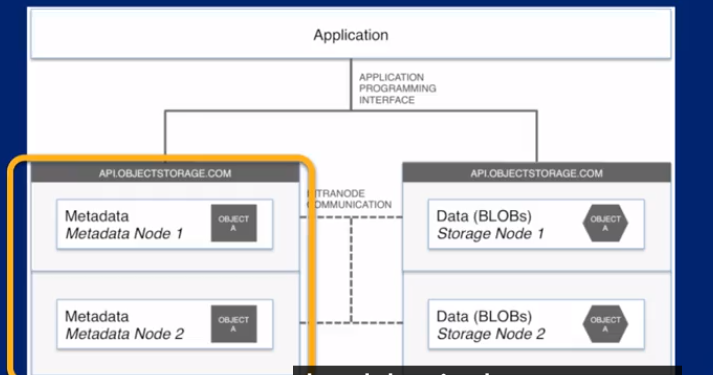
data lake summary

week5 - big data management
针对大数据,传统DBMS 需要提高的地方

some solutiion

from DBMS to BDMS
BDMS 应该具有的特征



BASE 就是基于CAP理论的

一些常用的BDMS及其优缺点
Redis: an enhanced key-value store




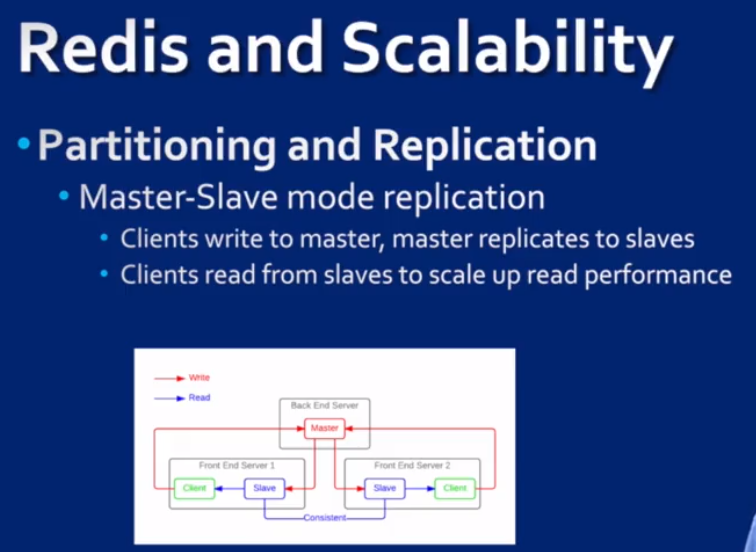
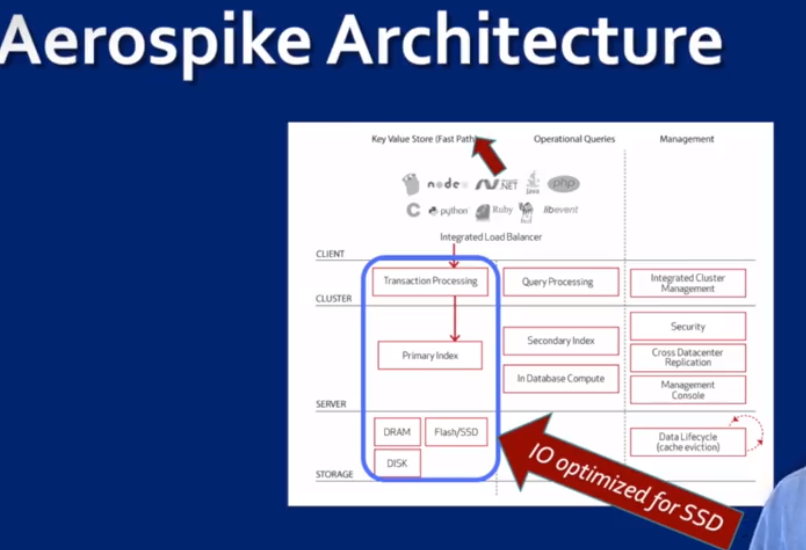
Aerospike: a new generation KV store
这是一个分布式NoSQL database + KV store. 是强一致性的



AsterixDB: a DBMS for semistructured data. 大家都知道的mongodb 以json 格式存储j数据, 这个Asterix 和 mongodb 类似. 它提供ACID保证.

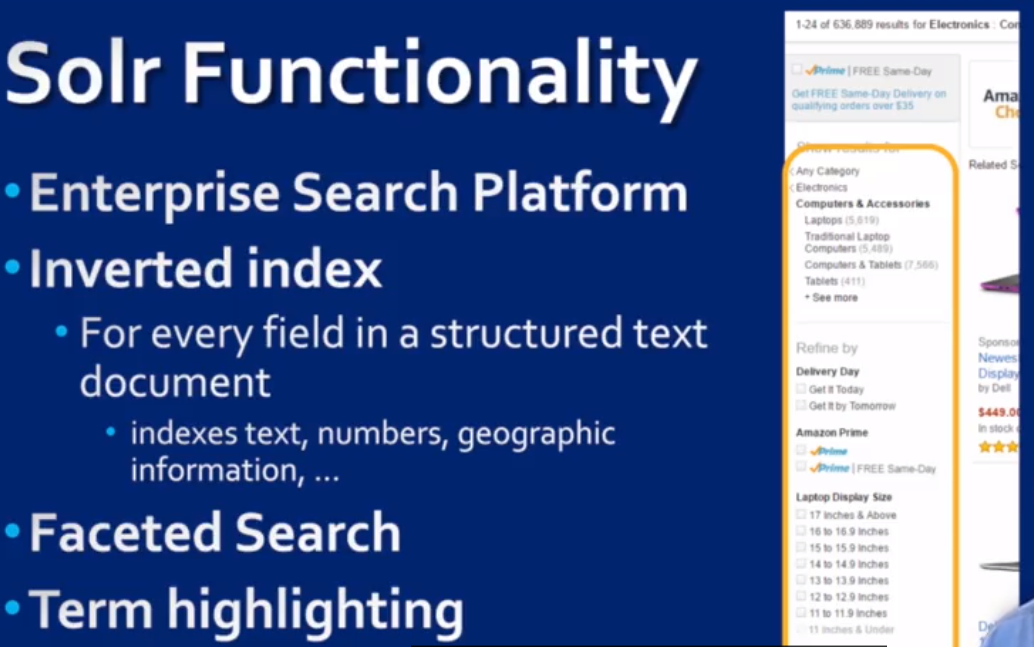
Solr : Text data searching. 基于Lucene的
应该是一种search engine, 不知道和 ES 什么区别.

反向索引,至少要包含 doc id list, 也可以包含更多信息

除了full text search, 还有下面的功能
Vertica:a columnar DBMS

Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)的更多相关文章
- Coursera, Big Data 2, Modeling and Management Systems (week 1/2/3)
Introduction to data management 整个coures 2 是讲data management and storage 的,主要内容就是分布式文件系统,HDFS, Redis ...
- Coursera, Big Data 3, Integration and Processing (week 4)
Week 4 Big Data Precessing Pipeline 上图可以generalize 成下图,也就是Big data pipeline some high level processi ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data KNime - GUI based Spark MLlib - inside Spark CRISP-DM Week 2, ...
- Coursera, Big Data 3, Integration and Processing (week 5)
Week 5, Big Data Analytics using Spark Programing in Spark Spark Core: Programming in Spark us ...
- Coursera, Big Data 3, Integration and Processing (week 1/2/3)
This is the 3rd course in big data specification courses. Data model reivew 1, data model 的特点: Struc ...
- Coursera, Big Data 1, Introduction (week 3)
什么是分布式文件系统?为什么需要分布式文件系统? 如果文件系统可以管理用网络连接的很多个存储单元,叫分布式文件系统. 分布式文件系统提供了数据可扩展性,容错性,高并发. 这些是传统文件系统不具有的. ...
- Coursera, Big Data 1, Introduction (week 1/2)
Status: week 2 done. Week 1, 主要讲了大数据的的来源 - 机器产生的数据,人产生的数据(比如社交软件上的update, 一般是unstructed data), 组织产生的 ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
- [label][Node.js] Three content management systems base on Node.js
1. Keystonejs http://keystonejs.com/ 2. Apostrophe http://apostrophenow.org/
随机推荐
- How Cigna Tuned Its Spark Streaming App for Real-time Processing with Apache Kafka
Explore the configuration changes that Cigna’s Big Data Analytics team has made to optimize the perf ...
- 19.java反射入门
一.反射机制是什么反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性:这种动态获取的信息以及动态调用对象的方法的功能称为jav ...
- 使用serialize时多数据传递
class CartList(APIView): #定义编辑方法 def post(self,request): username = request.POST.get('username') # p ...
- python小白——进阶之路——day1天---认识python和变量、注释
###-python的认知 89年开发的语言,创始人范罗苏姆(Guido van Rossum),别称:龟叔(Guido) (1)版本: python2.x原码不规范,重复较多 python3x:原码 ...
- JS&Java实现常见算法面试题
Github上的算法repo地址:https://github.com/qcer/Algo-Practice (如果你觉得有帮助,可以给颗星星收藏之~~~) 一.Java实现部分 参见随笔分类的算法部 ...
- React-关于react的思考
声明式开发 减少dom操作,减少代码量 可以与其他框架并存 组件化开发 单向数据流 视图层框架 大型项目需要与其他数据层框架一起使用 函数式编程 方便自动化测试
- JShell脚本工具
JShell脚本工具是JDK9的新特性 什么时候会用到 JShell 工具呢,当我们编写的代码非常少的时候,而又不愿意编写类,main方法,也不愿意去编译和运行,这个时候可以使用JShell工具.启动 ...
- 【zabbix教程系列】二、zabbix特点
一.度量收集 从任何设备,系统,应用上收集指标,收集指标的方法有: 多平台zabbix代理 SNMP and IPMI 代理 无代理监控用户服务 自定义方法 计算和聚合 用户端web监控 二.问题发 ...
- ViewPager + TabLayout + Fragment + MediaPlayer的使用
效果图 在gradle里导包 implementation 'com.android.support:design:28.0.0' activity_main <?xml version=&q ...
- AngularJS 1.x系列:Node.js安装及npm常用命令(1)
1. Node.js安装 1.1 Node.js下载 Node.js官网:https://nodejs.org 当前下载版本(含npm):Latest LTS Version: v6.10.3 (in ...