吴裕雄--天生自然 PYTHON数据分析:威斯康星乳腺癌(诊断)数据分析(续一)
drop_list1 = ['perimeter_mean','radius_mean','compactness_mean','concave points_mean','radius_se','perimeter_se','radius_worst','perimeter_worst','compactness_worst','concave points_worst','compactness_se','concave points_se','texture_worst','area_worst']
x_1 = x.drop(drop_list1,axis = 1 ) # do not modify x, we will use it later
x_1.head()
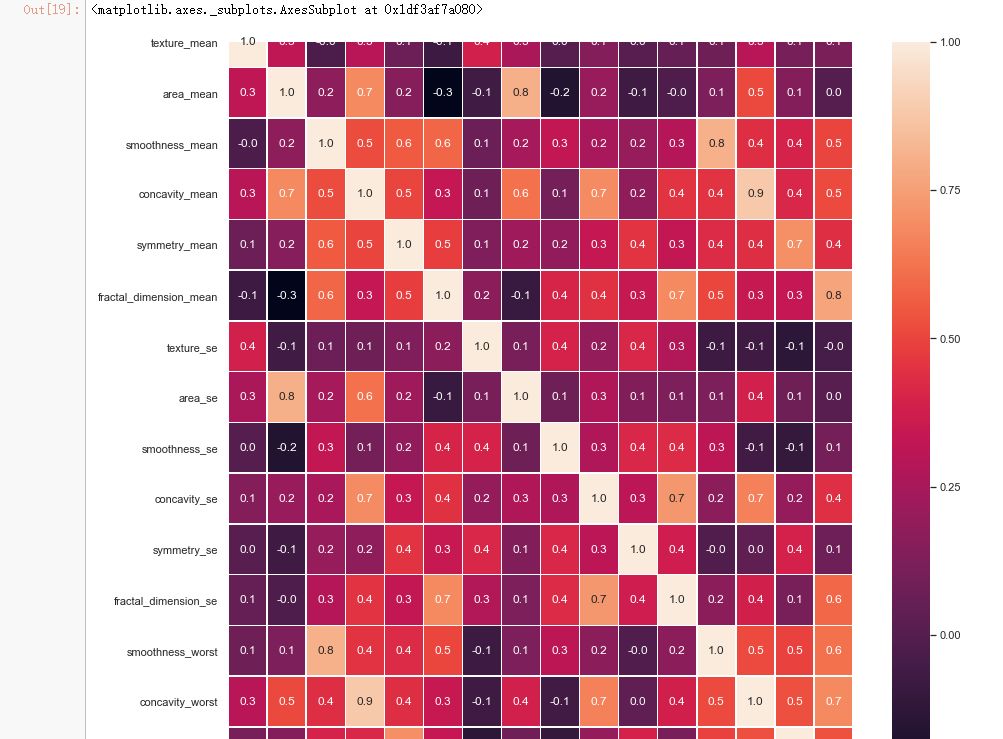
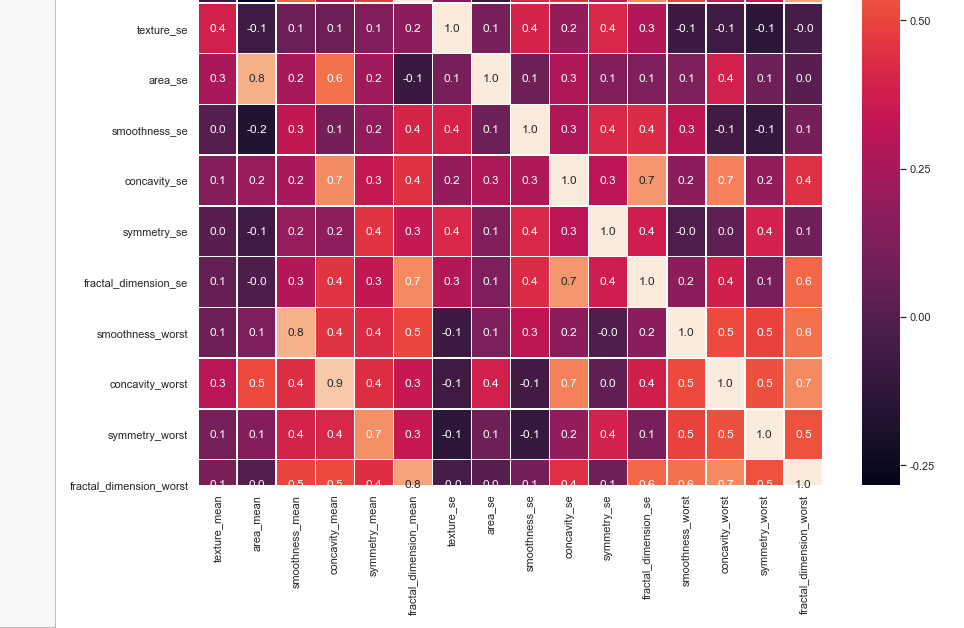
#correlation map
f,ax = plt.subplots(figsize=(14, 14))
sns.heatmap(x_1.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax)
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score,confusion_matrix
from sklearn.metrics import accuracy_score # split data train 70 % and test 30 %
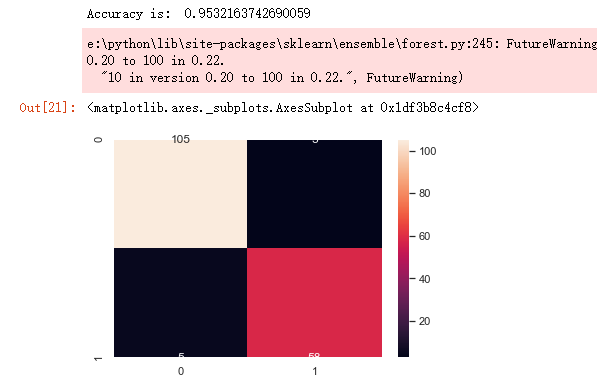
x_train, x_test, y_train, y_test = train_test_split(x_1, y, test_size=0.3, random_state=42) #random forest classifier with n_estimators=10 (default)
clf_rf = RandomForestClassifier(random_state=43)
clr_rf = clf_rf.fit(x_train,y_train) ac = accuracy_score(y_test,clf_rf.predict(x_test))
print('Accuracy is: ',ac)
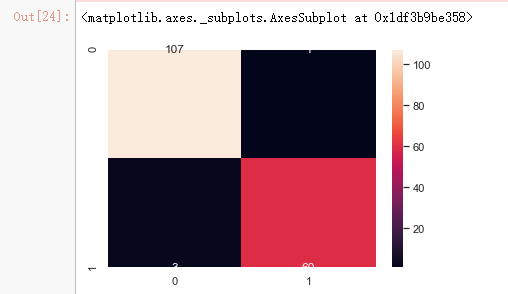
cm = confusion_matrix(y_test,clf_rf.predict(x_test))
sns.heatmap(cm,annot=True,fmt="d")
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# find best scored 5 features
select_feature = SelectKBest(chi2, k=5).fit(x_train, y_train)
print('Score list:', select_feature.scores_)
print('Feature list:', x_train.columns)

x_train_2 = select_feature.transform(x_train)
x_test_2 = select_feature.transform(x_test)
#random forest classifier with n_estimators=10 (default)
clf_rf_2 = RandomForestClassifier()
clr_rf_2 = clf_rf_2.fit(x_train_2,y_train)
ac_2 = accuracy_score(y_test,clf_rf_2.predict(x_test_2))
print('Accuracy is: ',ac_2)
cm_2 = confusion_matrix(y_test,clf_rf_2.predict(x_test_2))
sns.heatmap(cm_2,annot=True,fmt="d")
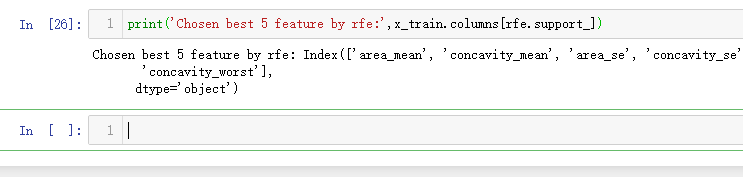
from sklearn.feature_selection import RFE
# Create the RFE object and rank each pixel
clf_rf_3 = RandomForestClassifier()
rfe = RFE(estimator=clf_rf_3, n_features_to_select=5, step=1)
rfe = rfe.fit(x_train, y_train)
print('Chosen best 5 feature by rfe:',x_train.columns[rfe.support_])
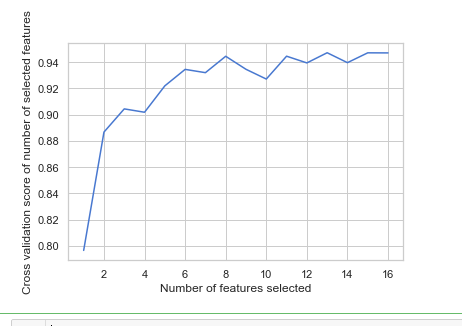
from sklearn.feature_selection import RFECV # The "accuracy" scoring is proportional to the number of correct classifications
clf_rf_4 = RandomForestClassifier()
rfecv = RFECV(estimator=clf_rf_4, step=1, cv=5,scoring='accuracy') #5-fold cross-validation
rfecv = rfecv.fit(x_train, y_train) print('Optimal number of features :', rfecv.n_features_)
print('Best features :', x_train.columns[rfecv.support_])
# Plot number of features VS. cross-validation scores
import matplotlib.pyplot as plt
plt.figure()
plt.xlabel("Number of features selected")
plt.ylabel("Cross validation score of number of selected features")
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
plt.show()
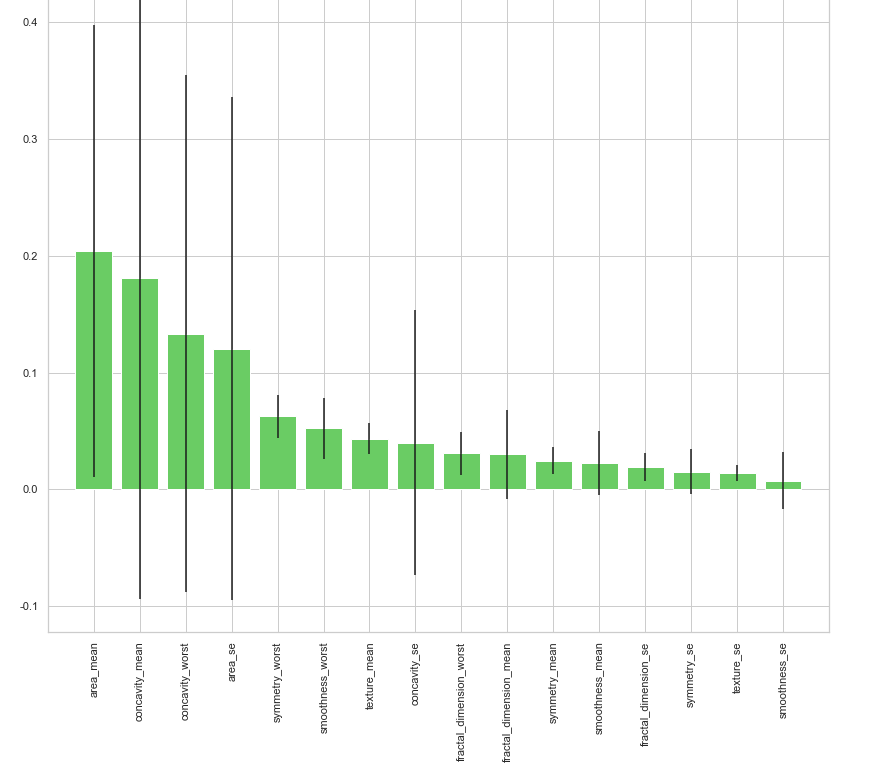
clf_rf_5 = RandomForestClassifier()
clr_rf_5 = clf_rf_5.fit(x_train,y_train)
importances = clr_rf_5.feature_importances_
std = np.std([tree.feature_importances_ for tree in clf_rf.estimators_],
axis=0)
indices = np.argsort(importances)[::-1] # Print the feature ranking
print("Feature ranking:") for f in range(x_train.shape[1]):
print("%d. feature %d (%f)" % (f + 1, indices[f], importances[indices[f]])) # Plot the feature importances of the forest plt.figure(1, figsize=(14, 13))
plt.title("Feature importances")
plt.bar(range(x_train.shape[1]), importances[indices],
color="g", yerr=std[indices], align="center")
plt.xticks(range(x_train.shape[1]), x_train.columns[indices],rotation=90)
plt.xlim([-1, x_train.shape[1]])
plt.show()

# split data train 70 % and test 30 %
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)
#normalization
x_train_N = (x_train-x_train.mean())/(x_train.max()-x_train.min())
x_test_N = (x_test-x_test.mean())/(x_test.max()-x_test.min()) from sklearn.decomposition import PCA
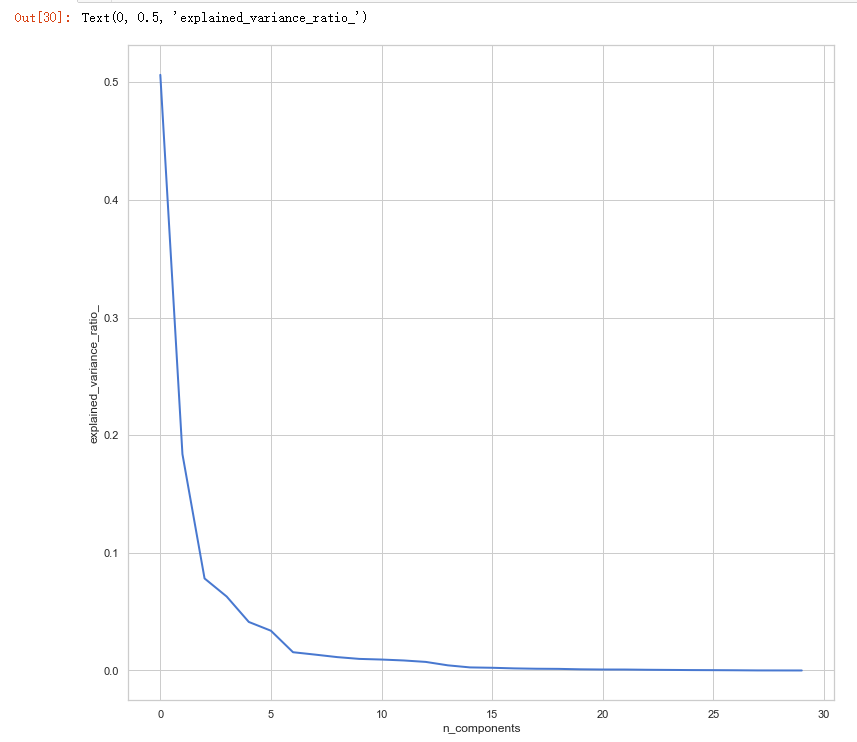
pca = PCA()
pca.fit(x_train_N) plt.figure(1, figsize=(14, 13))
plt.clf()
plt.axes([.2, .2, .7, .7])
plt.plot(pca.explained_variance_ratio_, linewidth=2)
plt.axis('tight')
plt.xlabel('n_components')
plt.ylabel('explained_variance_ratio_')
吴裕雄--天生自然 PYTHON数据分析:威斯康星乳腺癌(诊断)数据分析(续一)的更多相关文章
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:葡萄酒分析
# import pandas import pandas as pd # creating a DataFrame pd.DataFrame({'Yes': [50, 31], 'No': [101 ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- 吴裕雄--天生自然 python数据分析:医疗费数据分析
import numpy as np import pandas as pd import os import matplotlib.pyplot as pl import seaborn as sn ...
- 吴裕雄--天生自然 PYTHON语言数据分析:ESA的火星快车操作数据集分析
import os import numpy as np import pandas as pd from datetime import datetime import matplotlib imp ...
- 吴裕雄--天生自然 python语言数据分析:开普勒系外行星搜索结果分析
import pandas as pd pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]}) pd.DataFrame({'Bob': ['I liked i ...
- 吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results import numpy as np import ...
随机推荐
- Java架构师笔记-你必须掌握的 21 个 Java 核心技术!(干货)
闲来无事,师长一向不(没)喜(有)欢(钱)凑热闹,倒不如趁着这时候复盘复盘.而写这篇文章的目的是想总结一下自己这么多年来使用java的一些心得体会,希望可以给大家一些经验,能让大家更好学习和使用Jav ...
- winEdt打开tex文件报错解决方法
写论文真的是不断遇到各种困难啊,这个Latex软件就很多,好不容易中个A1区的文章,期刊说更新了新的模板就下载了,忽然发现打开有reading error,看不到一点内容,神奇的是竟然可以运行.这样的 ...
- android仿网易云音乐引导页、仿书旗小说Flutter版、ViewPager切换、爆炸菜单、风扇叶片效果等源码
Android精选源码 复现网易云音乐引导页效果 高仿书旗小说 Flutter版,支持iOS.Android Android Srt和Ass字幕解析器 Material Design ViewPage ...
- 4. 监控利器nagios手把手企业级实战第三部
1.nagios图形监控显示和管理服务器 虽然能显示,能报警.但是我们企业工作中需要一个历史趋势图. nagios只开放核心,插件是单独的形式,图像也一样,是插件或者整合的方式.所以可能看起来很多,这 ...
- beta函数分布图
set.seed(1) x<-seq(-5,5,length.out=10000) a = c(.5,0.6, 0.7, 0.8, 0.9) b = c(.5, 1, 1, 2, 5) colo ...
- C# 扩张方法的语法
using System; namespace ConsoleApp { class Program { static void Main(string[] args) { string str = ...
- British postal system to launch parcel postboxes
1 单词 parcel n. 包裹 pilot n. 试行计划 2 句子 1400 of the new boxes will be installed at 30 locations across ...
- mysql琐碎操作杂记
1.索引相关 查看表索引 show index from `user` 查看sql的执行计划 explain select * from where user 2.存储过程相关 查看存储过程 show ...
- 实现TabControl 选项卡首个标签缩进的方法
借用一张网图说明需求 在网上找了一圈,没有找到直接通过API或者重绘TabControl 的解决方法,最后灵机一动想到了一个折(tou)中(lan)的解决办法 Tab1.TabPages.Clear( ...
- VirtualBox虚拟机安装
目录 安装前准备 1.开始安装,安装很简单,直接上图 2.设置全局路径,这里主要是方便以后创建虚拟机的时候不用每次都去选择存放位置,默认是存放到C盘 安装前准备 系统:Windows 10 专业版 软 ...