Coursera, Big Data 3, Integration and Processing (week 1/2/3)
This is the 3rd course in big data specification courses.
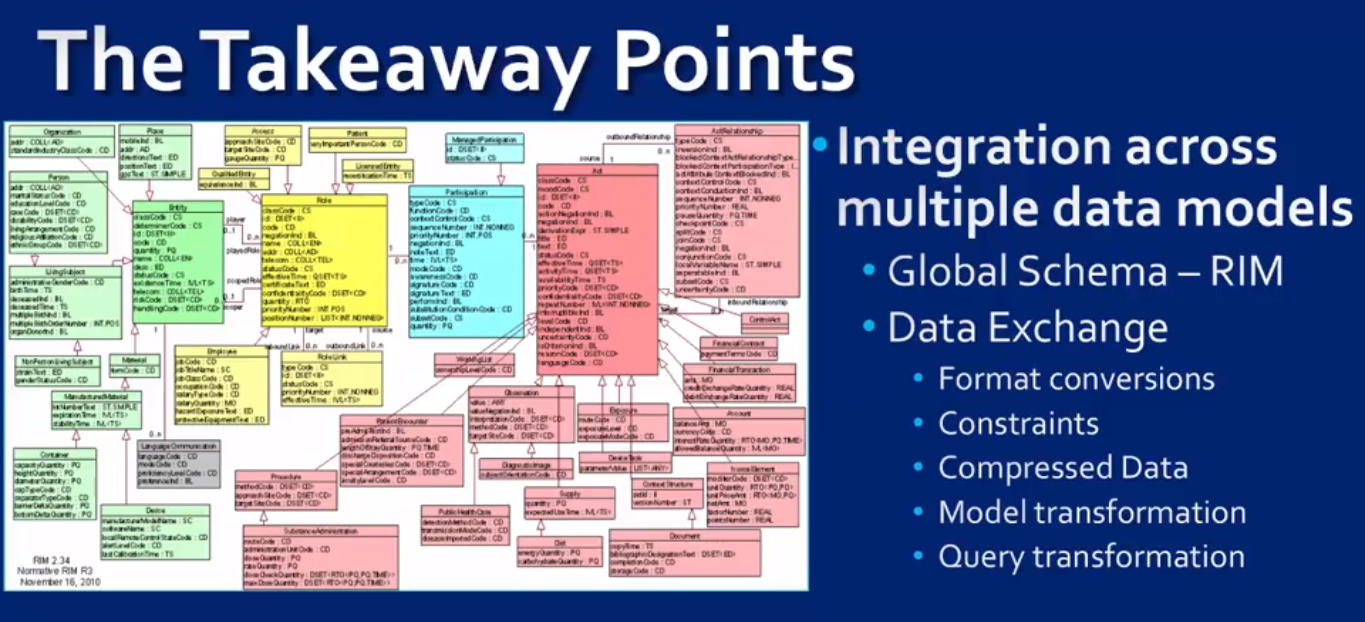
Data model reivew
1, data model 的特点: Structured, operations on it, constrains.
2. different types of data model
Retrieving data (week 1/2)
Querying data from ralational DB.

query data from mongodb











输出如下,注意第3条记录 
Big data integration (week3)
infomation integration 就是从多个infomation source 取数据来完成一个task

big data 主要的问题是 many sources, 两个solution 是pay-as-you-go, probabilistic schema mapping.
probabilitistic schema mapping 感觉是一种自动计算出 integration schema 的方法.






Industry examples for big data integration and processing
using Splunk and Datameer(used in digital music industry)
Coursera, Big Data 3, Integration and Processing (week 1/2/3)的更多相关文章
- Coursera, Big Data 3, Integration and Processing (week 4)
Week 4 Big Data Precessing Pipeline 上图可以generalize 成下图,也就是Big data pipeline some high level processi ...
- Coursera, Big Data 3, Integration and Processing (week 5)
Week 5, Big Data Analytics using Spark Programing in Spark Spark Core: Programming in Spark us ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data KNime - GUI based Spark MLlib - inside Spark CRISP-DM Week 2, ...
- Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)
week4 streaming data format 下面讲 data lakes schema-on-read: 从数据源读取raw data 直接放到 data lake 里,然后再读到mode ...
- Coursera, Big Data 2, Modeling and Management Systems (week 1/2/3)
Introduction to data management 整个coures 2 是讲data management and storage 的,主要内容就是分布式文件系统,HDFS, Redis ...
- Coursera, Big Data 1, Introduction (week 3)
什么是分布式文件系统?为什么需要分布式文件系统? 如果文件系统可以管理用网络连接的很多个存储单元,叫分布式文件系统. 分布式文件系统提供了数据可扩展性,容错性,高并发. 这些是传统文件系统不具有的. ...
- Coursera, Big Data 1, Introduction (week 1/2)
Status: week 2 done. Week 1, 主要讲了大数据的的来源 - 机器产生的数据,人产生的数据(比如社交软件上的update, 一般是unstructed data), 组织产生的 ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
- In-Stream Big Data Processing
http://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/ Overview In recent y ...
随机推荐
- 【转】Android中保持Service的存活
这几天一直在准备考试,总算有个半天时间可以休息下,写写博客. 如何让Service keep alive是一个很常见的问题. 在APP开发过程中,需要Service持续提供服务的应用场景太多了,比如闹 ...
- 监控elssticSearch健康状态
[4ajr@elk1 scripts]$ curl 172.30.210.175:9200/_cat/health [4ajr@elk1 scripts]$ cat check_es_healthy. ...
- AI adanet
adanet是一个基于Tensorflow的轻量级框架,只需要很少的专业干预,就可以自动学习出高质量的模型.在最近的AutoML成果上构建,既快速又灵活,还可以保证学习质量. adanet提供通用框架 ...
- Parallel 类并行任务(仅仅当执行耗时操作时,才有必要使用)
using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using S ...
- Python变量的本质与intern机制
变量的存储 a = 'abc' 理解:①先在内存中生成一个字符串‘abc’ ②可以把比变量名a看做一个便利贴,然后将a贴到‘abc’中 ③注意顺序,是生成‘abc’,然后再创建a指向‘abc’ ...
- c++学习之初话 函数指针和函数对象 的因缘
函数指针可以方便我们调用函数,但采用函数对象,更能体现c++面向对象的程序特性. 函数对象的本质:()运算符的重载.我们通过一段代码来感受函数指针和函数对象的使用: int AddFunc(int a ...
- 解决hash冲突的三个方法
通过构造性能良好的哈希函数,可以减少冲突,但一般不可能完全避免冲突,因此解决冲突是哈希法的另一个关键问题.创建哈希表和查找哈希表都会遇到冲突,两种情况下解决冲突的方法应该一致.下面以创建哈希表为例,说 ...
- 2019-04-03 研究EasyWeb有感
今天从往常睡到11点多才起床的状态中一下子转回9点前起床,起床第一件事就是开始研究这框架 1. 根据这框架的说明,首先搭建IDEA开发环境,下载.破解:当从EasyWeb官网下载了两个框架(一个是前端 ...
- mysql client--笔记-修改密码-登录-查看数据库-创建数据库
1 登录 mysql client 打开 mysql client -输入密码 123 回车 2 show database; ---显示数据库 3 切换数据库:use mysql 4 describ ...
- 清北学堂part1
睡眠质量相当高的一天(滑稽) 整一整都学了啥 1:高精度(相当水,毕竟学过) 2:模运算(?! 这还要讲?) 3:快速幂(还要谢一位学习高数时间为我们讲解的同学...不得不说真的有效,快速幂已经是随手 ...