吴裕雄 python 机器学习——分类决策树模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor def load_data():
'''
加载用于分类问题的数据集。数据集采用 scikit-learn 自带的 iris 数据集
'''
# scikit-learn 自带的 iris 数据集
iris=datasets.load_iris()
X_train=iris.data
y_train=iris.target
return train_test_split(X_train, y_train,test_size=0.25,random_state=0,stratify=y_train) #分类决策树DecisionTreeClassifier模型
def test_DecisionTreeClassifier(*data):
X_train,X_test,y_train,y_test=data
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
print("Training score:%f"%(clf.score(X_train,y_train)))
print("Testing score:%f"%(clf.score(X_test,y_test))) # 产生用于分类问题的数据集
X_train,X_test,y_train,y_test=load_data()
# 调用 test_DecisionTreeClassifier
test_DecisionTreeClassifier(X_train,X_test,y_train,y_test)

def test_DecisionTreeClassifier_criterion(*data):
'''
测试 DecisionTreeClassifier 的预测性能随 criterion 参数的影响
'''
X_train,X_test,y_train,y_test=data
criterions=['gini','entropy']
for criterion in criterions:
clf = DecisionTreeClassifier(criterion=criterion)
clf.fit(X_train, y_train)
print("criterion:%s"%criterion)
print("Training score:%f"%(clf.score(X_train,y_train)))
print("Testing score:%f"%(clf.score(X_test,y_test))) # 调用 test_DecisionTreeClassifier_criterion
test_DecisionTreeClassifier_criterion(X_train,X_test,y_train,y_test)

def test_DecisionTreeClassifier_splitter(*data):
'''
测试 DecisionTreeClassifier 的预测性能随划分类型的影响
'''
X_train,X_test,y_train,y_test=data
splitters=['best','random']
for splitter in splitters:
clf = DecisionTreeClassifier(splitter=splitter)
clf.fit(X_train, y_train)
print("splitter:%s"%splitter)
print("Training score:%f"%(clf.score(X_train,y_train)))
print("Testing score:%f"%(clf.score(X_test,y_test))) # 调用 test_DecisionTreeClassifier_splitter
test_DecisionTreeClassifier_splitter(X_train,X_test,y_train,y_test)

def test_DecisionTreeClassifier_depth(*data,maxdepth):
'''
测试 DecisionTreeClassifier 的预测性能随 max_depth 参数的影响
'''
X_train,X_test,y_train,y_test=data
depths=np.arange(1,maxdepth)
training_scores=[]
testing_scores=[]
for depth in depths:
clf = DecisionTreeClassifier(max_depth=depth)
clf.fit(X_train, y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test)) ## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(depths,training_scores,label="traing score",marker='o')
ax.plot(depths,testing_scores,label="testing score",marker='*')
ax.set_xlabel("maxdepth")
ax.set_ylabel("score")
ax.set_title("Decision Tree Classification")
ax.legend(framealpha=0.5,loc='best')
plt.show() # 调用 test_DecisionTreeClassifier_depth
test_DecisionTreeClassifier_depth(X_train,X_test,y_train,y_test,maxdepth=100)

import os
import pydotplus from io import StringIO
from sklearn.tree import export_graphviz
from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor X_train,X_test,y_train,y_test=load_data()
clf = DecisionTreeClassifier()
clf.fit(X_train,y_train)
export_graphviz(clf,"F://out")


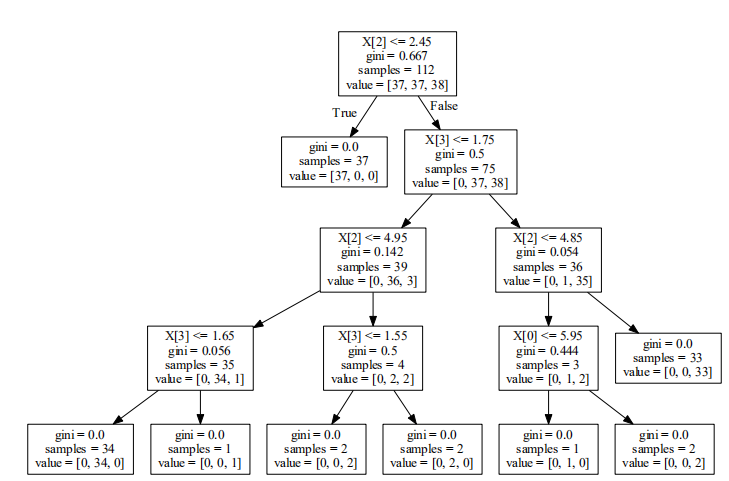
吴裕雄 python 机器学习——分类决策树模型的更多相关文章
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——核化PCAKernelPCA模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——KNN分类KNeighborsClassifier模型
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors, datasets from skle ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——模型选择分类问题性能度量
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import SVC from sklearn.datasets ...
随机推荐
- Spring常用的三种注入方式
好文要收藏,摘自:https://blog.csdn.net/a909301740/article/details/78379720 Spring通过DI(依赖注入)实现IOC(控制反转),常用的注入 ...
- docker 限制container容器使用内存大小,不限制swap
docker update --memory 20g --memory-swap -1 96b14c546d98 参考:https://my.oschina.net/Kanonpy/blog/2209 ...
- win 8.1 Your PC needs to be repaired修复过程
一.问题情况描述: 下班时,执行关闭系统命令,但硬盘灯一直亮着,因急着下班,所以直接长按电源键,装包回家... 到家后一段时间,启动电脑,但电脑蓝屏,提示“Your PC needs to be re ...
- Faster-RCNN理解
一.Faster-RCNN基本结构 该网络结构大致分为三个部分:卷积层得到高位图像特征feature maps.Region Proposal Network得到候选边框.classifier识别出物 ...
- php+redis实现消息队列
参考:http://www.cnblogs.com/lisqiong/p/6039460.html 参考:http://blog.csdn.net/shaobingj126/article/detai ...
- 第一次使用mybatis
程序使用mybatis的步骤: 1.配置mybatis 涉及到的配置文件有conf.xml和与实体类对应的映射配置文件 (1) conf.xml:配置数据库信息和需要加载的映射文件 <confi ...
- Windows FFMPEG开发环境配置
1.去FFMPEG网站上下载Dev版本的库,里面有我们需要的头文件和lib文件,然后下载Shared版本的库,里面有我们需要的dll文件 http://ffmpeg.zeranoe.com/build ...
- ABBYY FineReader 14OCR解锁
ABBYY FineReader 14是2017年新推的文字处理编辑软件,能够将图像扫描转换成文档处理.不论是在使用群体方面还是功能特性方面都是极好的. •确保扫描仪正确地连接到电脑,并将其打开.查阅 ...
- C3D视频特征提取
一.部署 1. 先把项目Clone下来 git clone https://github.com/jfzhang95/pytorch-video-recognition.git 2. 安装环境: Py ...
- Halcon Visinpro 破解版
目前测试过的破解版资料: halcon10 可用已测 完美破解 halcon12 可用已测 完美破解 halcon13 可用已测 完美破解 halcon17 可用已测 ...