[Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一、介绍
本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标题,时间)
二、网站信息
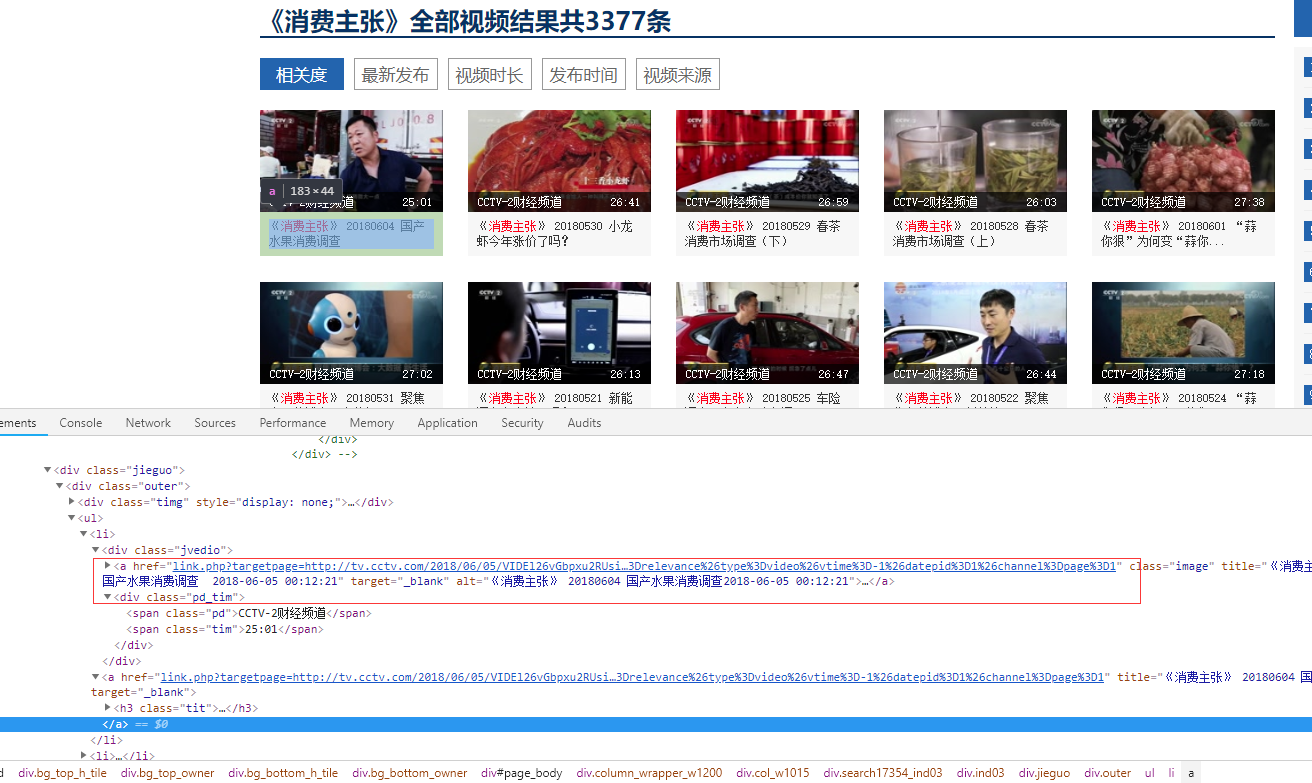
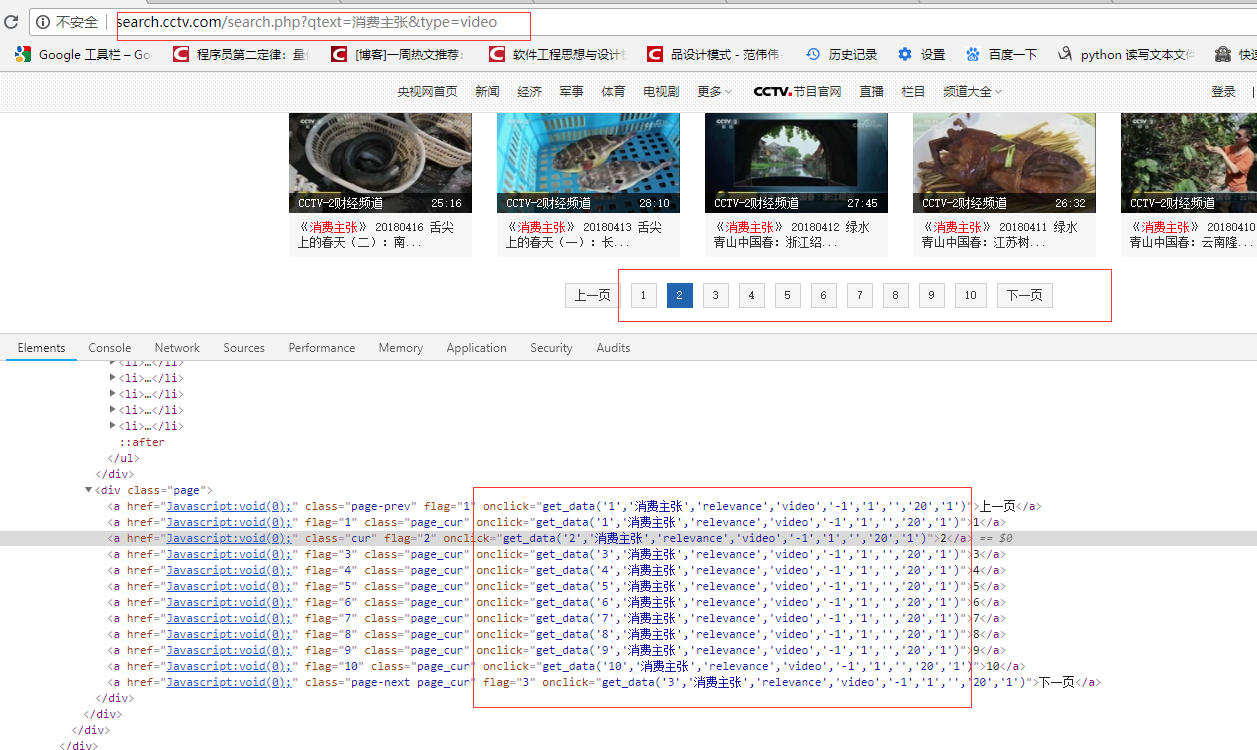
python 代码
# coding=utf-8
import os
import re
from selenium import webdriver
from datetime import datetime,timedelta
import time
from pyquery import PyQuery as pq
import re
import mongoDB
import datetime class consumer: def __init__(self):
#通过配置文件获取IEDriverServer.exe路径
# IEDriverServer ='C:\Program Files\Internet Explorer\IEDriverServer.exe'
# self.driver = webdriver.Ie(IEDriverServer)
# self.driver.maximize_window()
self.driver = webdriver.PhantomJS(service_args=['--load-images=false'])
# self.driver = driver = webdriver.Chrome()
self.driver.set_page_load_timeout(10)
self.driver.maximize_window()
self.db = mongoDB.mongoDbBase() def WriteLog(self, message,date):
fileName = os.path.join(os.getcwd(), 'consumer/' + date + '.txt')
with open(fileName, 'a') as f:
f.write(message)
# http://search.cctv.com/search.php?qtext=消费主张&type=video
def CatchData(self,url='http://search.cctv.com/search.php?qtext=%E6%B6%88%E8%B4%B9%E4%B8%BB%E5%BC%A0&type=video'):
error = ''
try:
self.driver.get(url)
time.sleep(1)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html) filename = datetime.datetime.now().strftime('%Y-%m-%d')
message = '{0},{1}'.format( '标题', '时间')
filename = datetime.datetime.now().strftime('%Y-%m-%d')
self.WriteLog(message, filename)
pages = doc("div[class='page']").find("a")
# 2018-06-05 00:12:21
pattern = re.compile("\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}")
for index in range(1,6):
url = "get_data('{0}', '消费主张', 'relevance', 'video', '-1', '1', '', '20', '1')".format(index) self.driver.execute_script(url)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html) Elements = doc("div[class='jvedio']").find("a")
for sub in Elements.items():
title = sub.attr('title').encode('utf8')
ts = pattern.findall(title)
strtime = ''
if ts and len(ts) == 1:
strtime = ts[0]
if strtime:
index = title.index(strtime)
title = title[0:index]
title = '\n{0},{1}'.format(title,strtime)
self.WriteLog(title, filename) except Exception, e1:
error = e1.message # def CatchData(self,url='http://search.cctv.com/search.php?qtext=%E6%B6%88%E8%B4%B9%E4%B8%BB%E5%BC%A0&type=video'):
# error = ''
# try:
# self.driver.get(url)
# time.sleep(1)
# selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
# doc = pq(selenium_html)
#
# filename = datetime.datetime.now().strftime('%Y-%m-%d')
#
# pages = doc("div[class='page']").find("a")
#
# for element in pages.items():
# url = element.attr('onclick').encode('utf8')
# # get_data('1','消费主张','relevance','video','-1','1','','20','1')
# # get_data('2', '消费主张', 'relevance', 'video', '-1', '1', '', '20', '1')
# print url
# self.driver.execute_script(url)
# selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
# doc = pq(selenium_html)
#
# Elements = doc("div[class='jvedio']").find("a")
# for sub in Elements.items():
# title = sub.attr('title').encode('utf8')
# print title
# title = '\n{0}'.format(title)
# self.WriteLog(title, filename)
# except Exception, e1:
# error = e1.message obj = consumer() obj.CatchData()
# obj.CatchContent('')
# obj.export('')
[Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息的更多相关文章
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之十六:Selenium +phantomjs 利用 pyquery抓取一点咨询数据
本篇主要是利用 pyquery来定位抓取数据,而不用xpath,通过和xpath比较,pyquery效率要高. 主要代码: # coding=utf-8 import os import re fro ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- [Python爬虫] 之二十二:Selenium +phantomjs 利用 pyquery抓取界面网站数据
一.介绍 本例子用Selenium +phantomjs爬取界面(https://a.jiemian.com/index.php?m=search&a=index&type=news& ...
- [Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一.介绍 本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息 二.网站信息 三.数据抓 ...
- [Python爬虫] 之十七:Selenium +phantomjs 利用 pyquery抓取梅花网数据
一.介绍 本例子用Selenium +phantomjs爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字: ...
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一.介绍 本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息. 给定关键字:视频:融合:电视 二 ...
随机推荐
- nodejs pm2配置使用教程
pm2是非常优秀工具,它提供对基于node.js的项目运行托管服务.它基于命令行界面,提供很多特性: 内置的负载均衡器等等,下面我们就一起来看看吧. 一.简介 pm2是一个带有负载均衡功能的应用进程管 ...
- Scrapy 笔记(三)
摘抄自Python 一.随机user-agent 的设置 关于配置和代码 这里我找了一个之前写好的爬虫,然后实现随机更换User-Agent,在settings配置文件如下: DOWNLOADER_M ...
- ubuntu下让进程在后台运行
(1)输入命令: nohup 你的shell命令 & (2)回车,使终端回到shell命令行: (3)使用第二第三条,完全屏蔽掉信号 用disown -h jobspec来使某个作业忽略HUP ...
- SCU 4442 Party
二分图的最小点权覆盖. 非常感谢巨巨@islands_的解答,还帮我画了一个图. 题目保证给出的边构成的图是一个二分图. 如果没有第三种类型的$frog$,那么问题就很简单了.即选择哪些点,覆盖住所有 ...
- Bzoj1202/洛谷P2294 [HNOI2005]狡猾的商人(带权并查集/差分约束系统)
题面 Bzoj 洛谷 题解 考虑带权并查集,设\(f[i]\)表示\(i\)的父亲(\(\forall f[i]<i\)),\(sum[i]\)表示\(\sum\limits_{j=fa[i]} ...
- shell sh bash 概念
在shell脚本的开头往往有一句话来定义使用哪种sh解释器来解释脚本.目前研发送测的shell脚本中主要有以下两种方式:(1) #!/bin/sh(2) #!/bin/bash以上两种方式有什么区别? ...
- navicat批量导入数据
1.excel表导入数据 根据数据表添加excel表内容 开始导入数据
- 20162325 金立清 S2 W6 C15
20162325 2017-2018-2 <程序设计与数据结构>第6周学习总结 教材学习内容概要 队列是先进先出(FIFO)的集合 队列是保存重复编码k值的一种有效结构 实现模拟时常用队列 ...
- Educational Codeforces Round 11 D. Number of Parallelograms 暴力
D. Number of Parallelograms 题目连接: http://www.codeforces.com/contest/660/problem/D Description You ar ...
- 使用辗转相除法求两个数的最大公因数(python实现)
数学背景: 整除的定义: 任给两个整数a,b,其中b≠0,如果存在一个整数q使得等式 a = bq 成立,我们就说是b整除 ...