Coursera, Big Data 3, Integration and Processing (week 5)
Week 5, Big Data Analytics using Spark
Programing in Spark

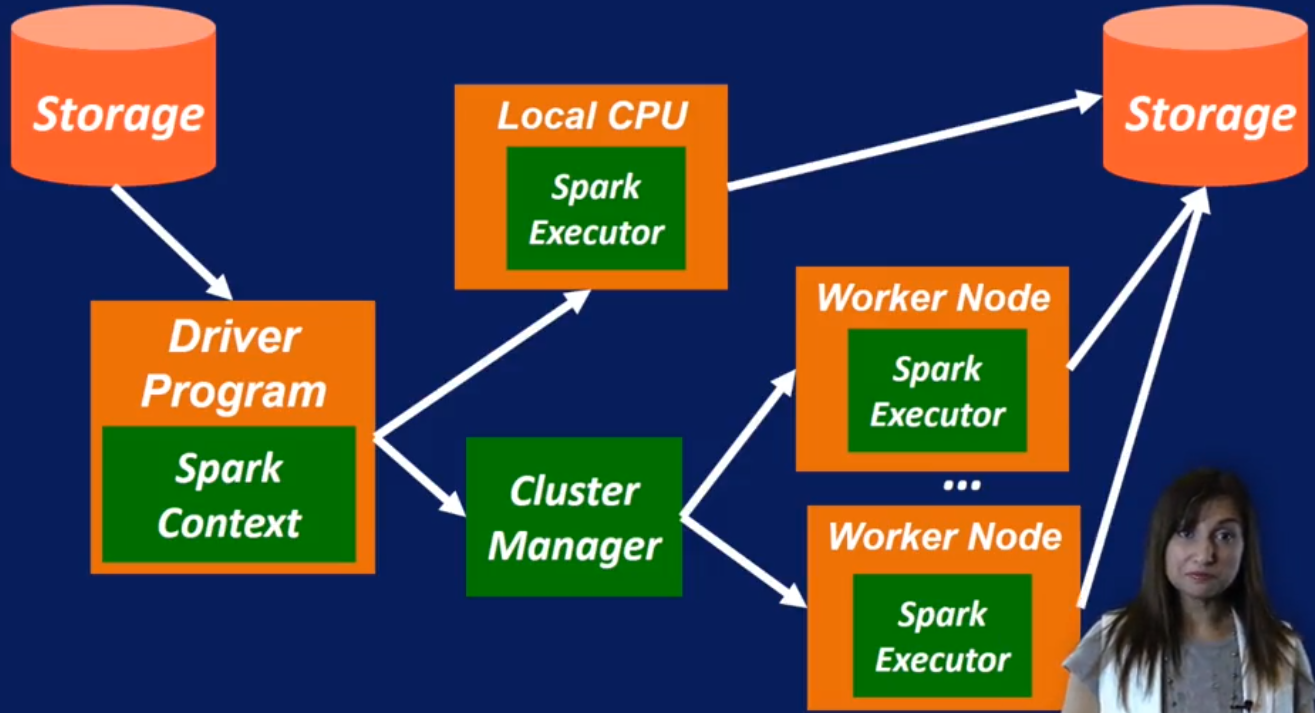
Spark Core: Programming in Spark using RDD in pipelines

RDD 创建过后,会有两种操作,Transformation 和 Action. 只有到了Action 阶段才会验证Transformation 操作是否正确,所以经常看到Action阶段有很多报错. 叫 lazy
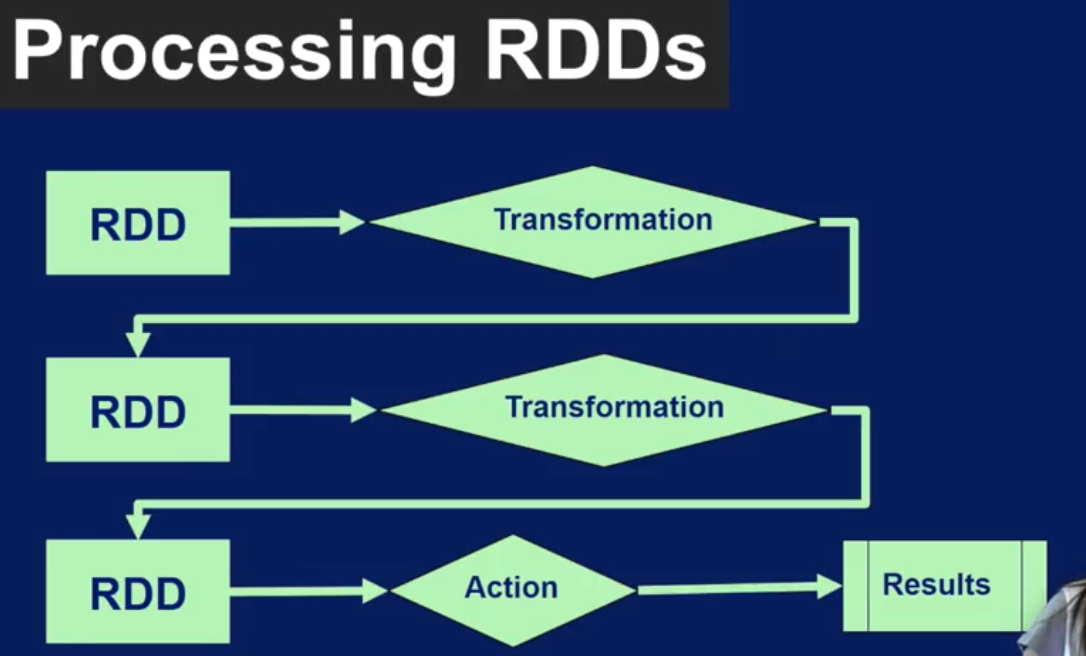
下图是一个具体的例子. 教程里提到了cache功能,比如从数据库query 数据放到RDD里,这个过程比较耗时,为了防止每次都去执行query操作,我们就可以把第一次的结果()也就是RDD) cache起来,但是注意使用cache 很耗内存,可能会造成瓶颈..

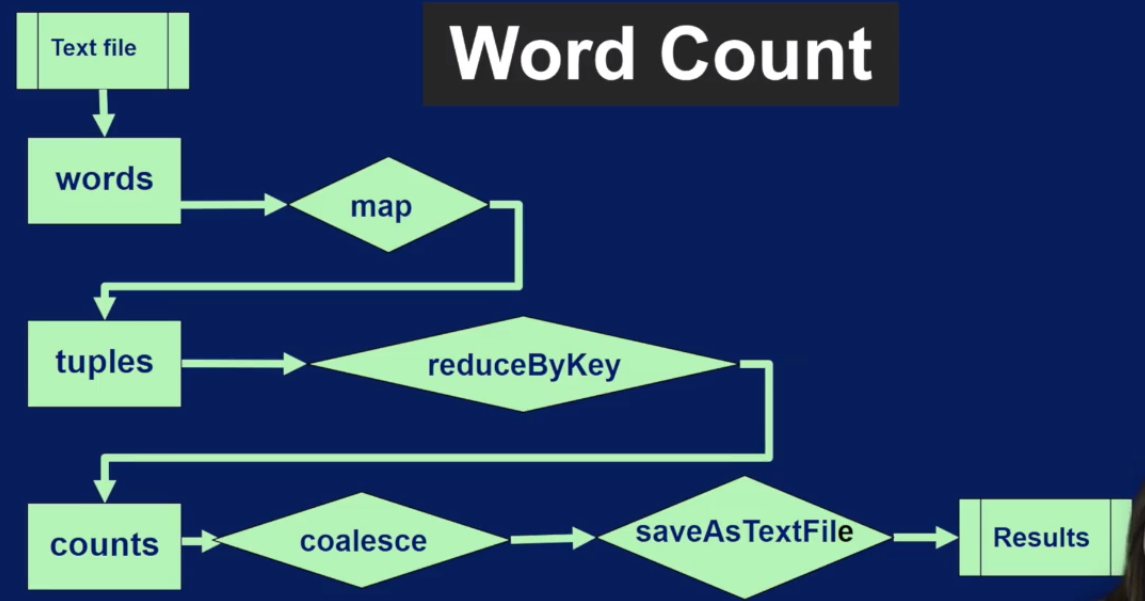

Spark Core: Transformation
RDD本身不能被改变,只能通过transformtion操作转成一个新的RDD

Map transformation

flatMap transfromation, 一对多
map 和 flatMap 是narrow tranformation. narrow transformation 只依赖于一个partition上的数据,并且 data suffering is not nessary.

Filter transformation

Coalesce transformation, 比如

上面谈的都是narrow transformation, 都是本地处理数据不需要在网络上传输数据。
接下来谈wide transformation
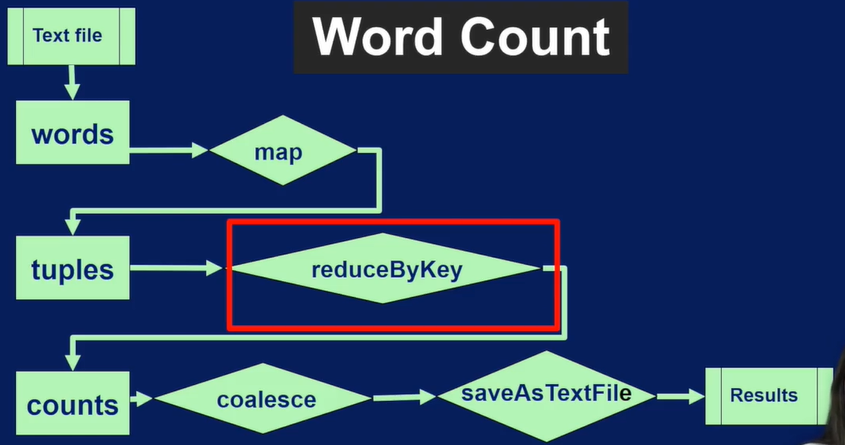
先看看reduceByKey 和 groupByKey 的区别.
groupByKey 需要跨节点的shuffle 操作,输出是一个由 初始数字 1 组成的列表
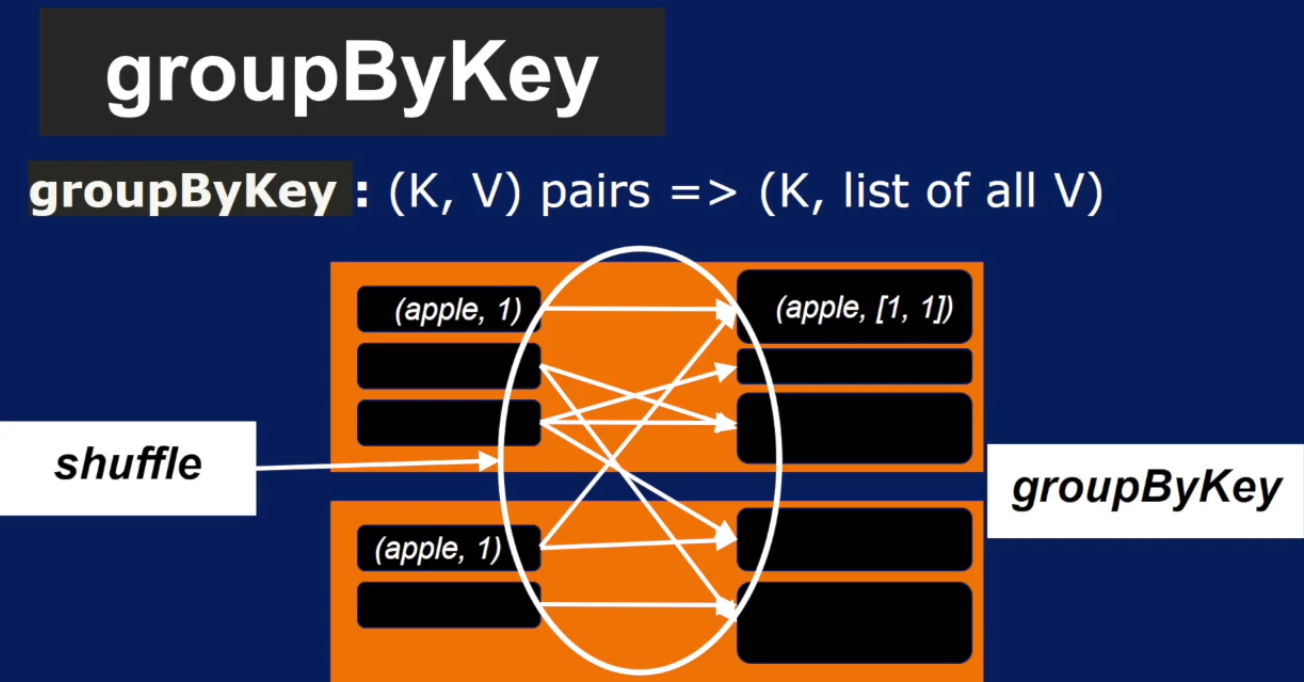
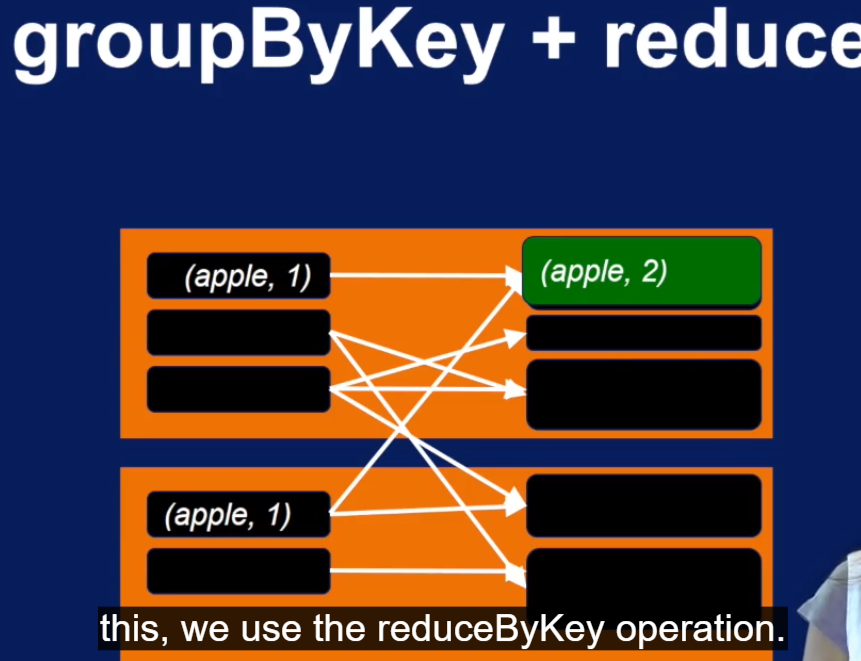
reduceByKey 其实就是 groupByKey + reduce
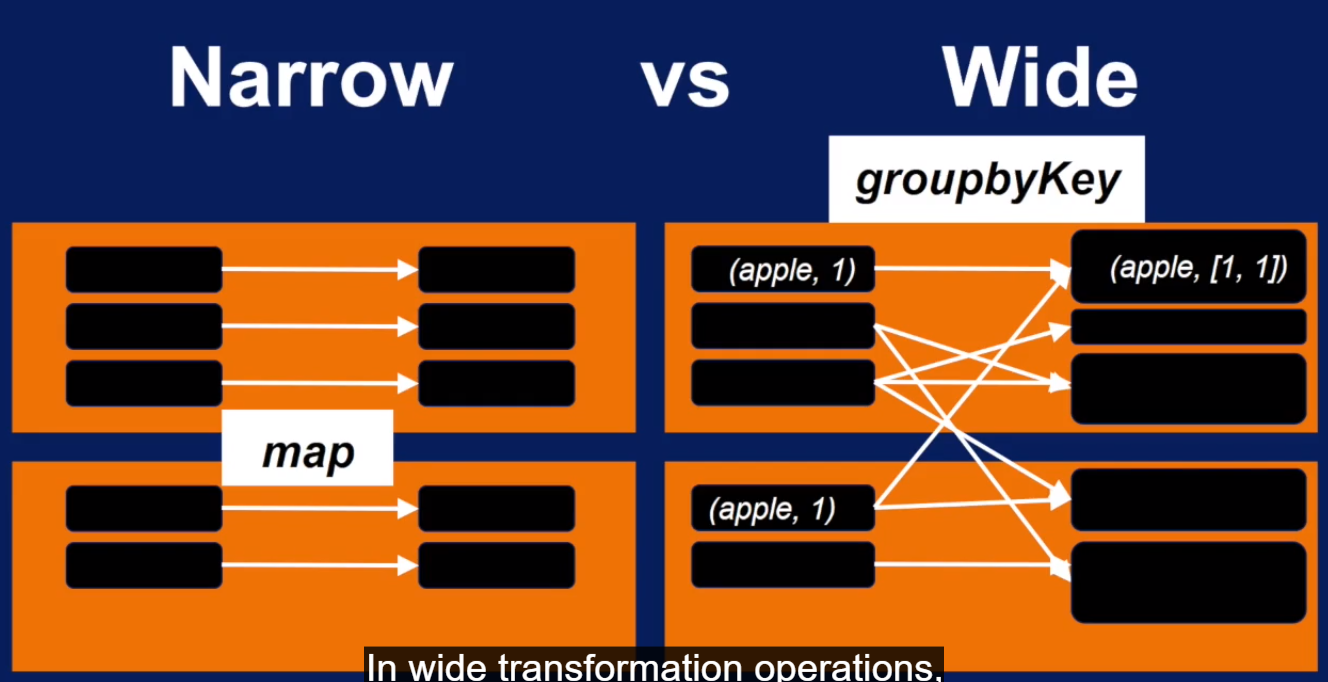
narrow transformation 和 wide transformation 区别: 就看有没有跨节点的 shuffle 操作, 也就是有没有跨节点取数据做操作
Spark Core: Actions

第一个Action操作是很常见的collect, 它从worker node 收集最终的结果数据copy到driver node.
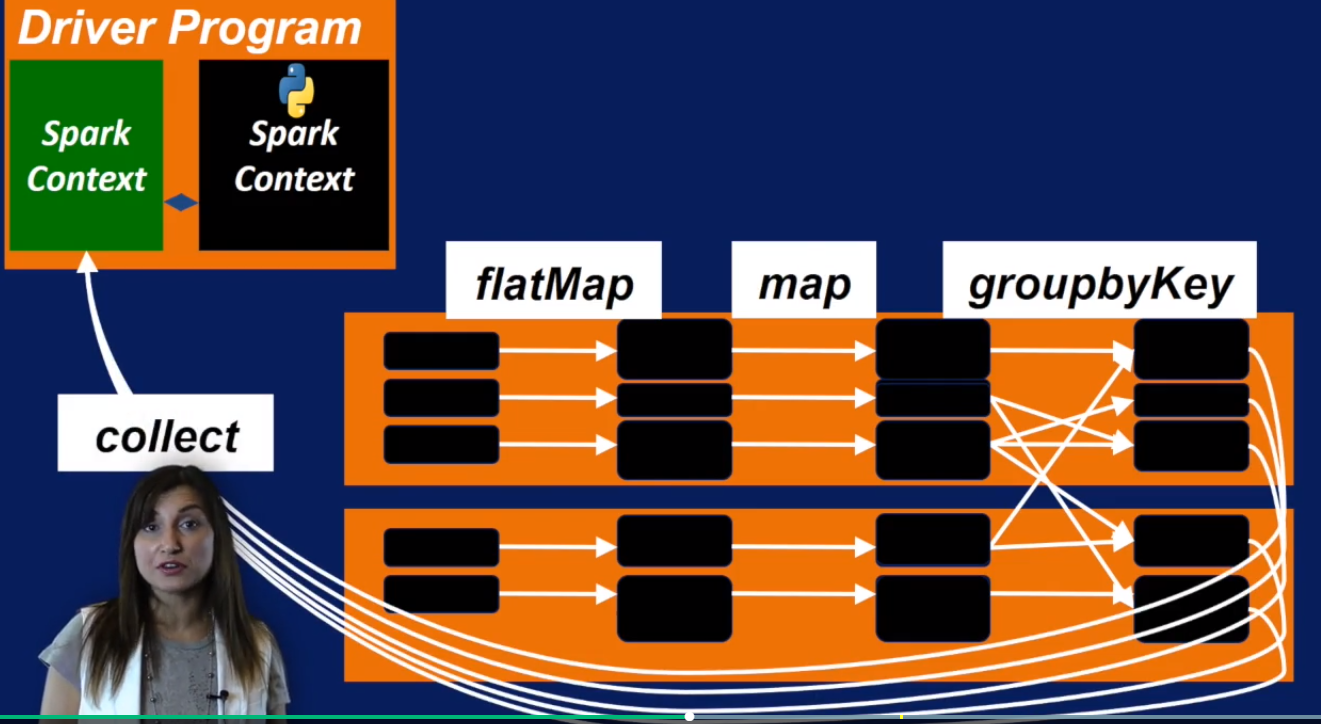

其中Reduce 最常用
Main models in Spark eco
Spark SQL
做什么的?优势?



Spark SQL 提供了API可以使query来的data转成 DataFrame

具体怎么做?


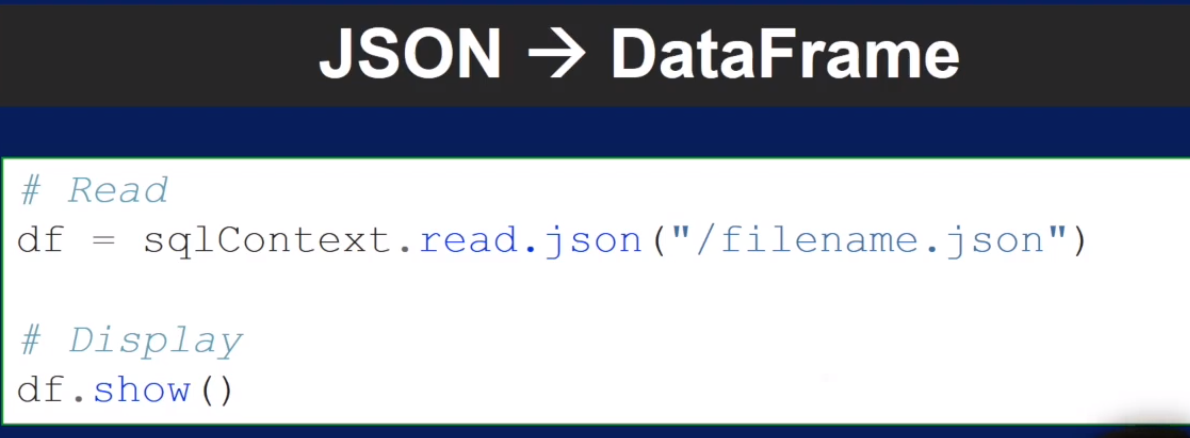


Spark SQL summary

Spark Streaming



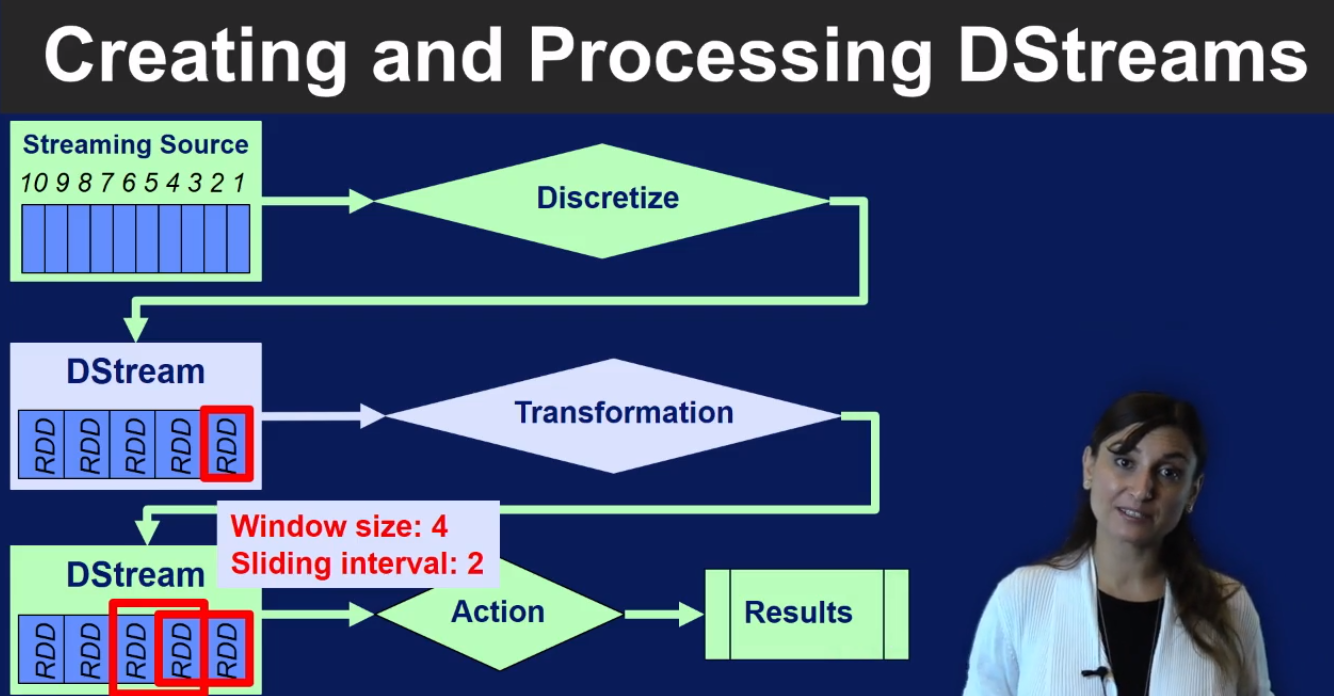
Spark Streaming summary

Spark MLlib





Spark GraphX





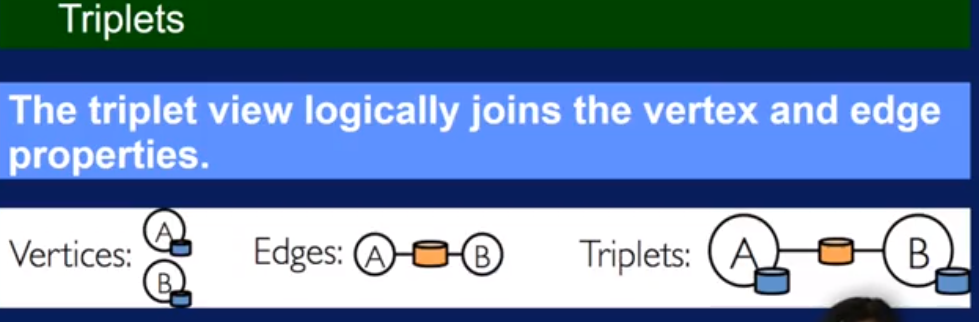
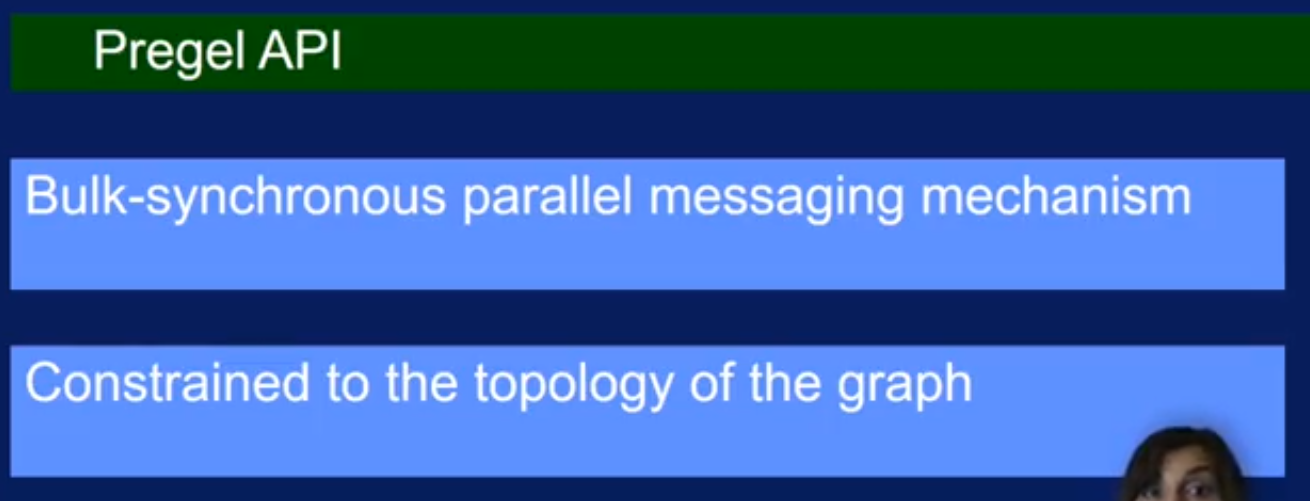
Spark GraphX summary

Coursera, Big Data 3, Integration and Processing (week 5)的更多相关文章
- Coursera, Big Data 3, Integration and Processing (week 1/2/3)
This is the 3rd course in big data specification courses. Data model reivew 1, data model 的特点: Struc ...
- Coursera, Big Data 3, Integration and Processing (week 4)
Week 4 Big Data Precessing Pipeline 上图可以generalize 成下图,也就是Big data pipeline some high level processi ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data KNime - GUI based Spark MLlib - inside Spark CRISP-DM Week 2, ...
- Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)
week4 streaming data format 下面讲 data lakes schema-on-read: 从数据源读取raw data 直接放到 data lake 里,然后再读到mode ...
- Coursera, Big Data 2, Modeling and Management Systems (week 1/2/3)
Introduction to data management 整个coures 2 是讲data management and storage 的,主要内容就是分布式文件系统,HDFS, Redis ...
- Coursera, Big Data 1, Introduction (week 3)
什么是分布式文件系统?为什么需要分布式文件系统? 如果文件系统可以管理用网络连接的很多个存储单元,叫分布式文件系统. 分布式文件系统提供了数据可扩展性,容错性,高并发. 这些是传统文件系统不具有的. ...
- Coursera, Big Data 1, Introduction (week 1/2)
Status: week 2 done. Week 1, 主要讲了大数据的的来源 - 机器产生的数据,人产生的数据(比如社交软件上的update, 一般是unstructed data), 组织产生的 ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
- In-Stream Big Data Processing
http://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/ Overview In recent y ...
随机推荐
- git、github、gitlab之间的关系
GIt-版本控制工具:GitHub-一个网站平台,提供给用户空间存储git仓储,保存用户的一些数据文档或者代码等:GitLab - 基于Git的项目管理软件. Git分布式版本控制系统 Git是一款自 ...
- PostgreSQL:Java使用CopyManager实现客户端文件COPY导入
在MySQL中,可以使用LOAD DATA INFILE和LOAD DATA LOCAL INFILE两种方式导入文本文件中的数据到数据库表中,速度非常快.其中LOAD DATA INFILE使用的文 ...
- 慢日志查询python flask sqlalchemy慢日志记录
engine = create_engine(ProdConfig.SQLALCHEMY_DATABASE_URI, echo=True) app = Flask(__name__) app.conf ...
- mybatis 错误
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.TooManyR ...
- Python OpenCV 图像处理初级使用
# -*- coding: utf-8 -*-"""Created on Thu Apr 25 08:11:32 2019 @author: jiangshan" ...
- JDK1.8源码(九)——java.util.LinkedHashMap 类
前面我们介绍了 Map 集合的一种典型实现 HashMap ,关于 HashMap 的特性,我们再来复习一遍: ①.基于JDK1.8的HashMap是由数组+链表+红黑树组成,相对于早期版本的 JDK ...
- iframe 自适应
<iframe src="http://www.fulibac.com" id="myiframe" scrolling="no" o ...
- SpringCloud(6)分布式配置中心Spring Cloud Config
1.Spring Cloud Config 简介 在分布式系统中,由于服务数量巨多,为了方便服务配置文件统一管理,实时更新,所以需要分布式配置中心组件.在Spring Cloud中,有分布式配置中心组 ...
- cookie跨域共享
domain和path属性,domain就是当前域,默认为请求的地址,如网址为www.jb51.net/test/test.aspx,那么domain默认为www.jb51.net,path默认就是当 ...
- 解决Jenkins邮件配置问题
最近要配置Jenkins邮箱,由于一直报如下错误,又没办法解决,所以想到了另外的办法发邮件. 我采用shell脚本执行python命令的方式来发邮件: #!/bin/bash cd /software ...