吴裕雄--天生自然 PYTHON数据分析:钦奈水资源管理分析
df = pd.read_csv("F:\\kaggleDataSet\\chennai-water\\chennai_reservoir_levels.csv")
df["Date"] = pd.to_datetime(df["Date"], format='%d-%m-%Y')
df.head()

import datetime def scatter_plot(cnt_srs, color):
trace = go.Scatter(
x=cnt_srs.index[::-1],
y=cnt_srs.values[::-1],
showlegend=False,
marker=dict(
color=color,
),
)
return trace cnt_srs = df["POONDI"]
cnt_srs.index = df["Date"]
trace1 = scatter_plot(cnt_srs, 'red') cnt_srs = df["CHOLAVARAM"]
cnt_srs.index = df["Date"]
trace2 = scatter_plot(cnt_srs, 'blue') cnt_srs = df["REDHILLS"]
cnt_srs.index = df["Date"]
trace3 = scatter_plot(cnt_srs, 'green') cnt_srs = df["CHEMBARAMBAKKAM"]
cnt_srs.index = df["Date"]
trace4 = scatter_plot(cnt_srs, 'purple') subtitles = ["Water Availability in Poondi reservoir - in mcft",
"Water Availability in Cholavaram reservoir - in mcft",
"Water Availability in Redhills reservoir - in mcft",
"Water Availability in Chembarambakkam reservoir - in mcft"
]
fig = tools.make_subplots(rows=4, cols=1, vertical_spacing=0.08,
subplot_titles=subtitles)
fig.append_trace(trace1, 1, 1)
fig.append_trace(trace2, 2, 1)
fig.append_trace(trace3, 3, 1)
fig.append_trace(trace4, 4, 1)
fig['layout'].update(height=1200, width=800, paper_bgcolor='rgb(233,233,233)')
py.iplot(fig, filename='h2o-plots')
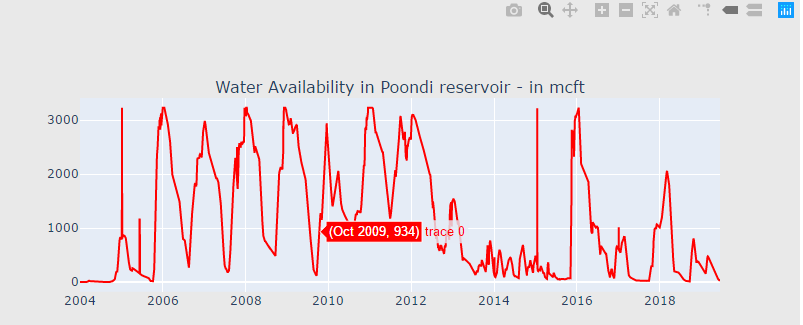
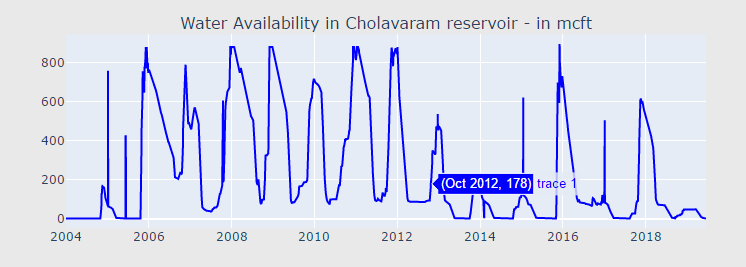

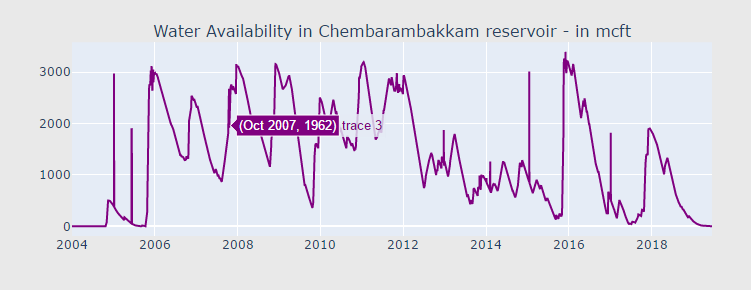
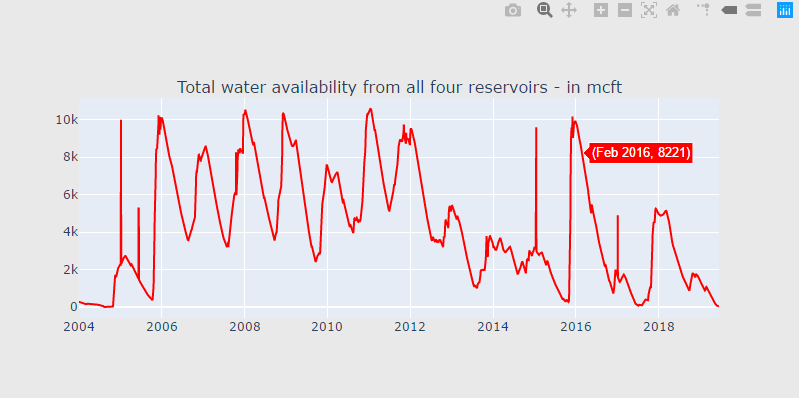
df["total"] = df["POONDI"] + df["CHOLAVARAM"] + df["REDHILLS"] + df["CHEMBARAMBAKKAM"]
df["total"] = df["POONDI"] + df["CHOLAVARAM"] + df["REDHILLS"] + df["CHEMBARAMBAKKAM"] cnt_srs = df["total"]
cnt_srs.index = df["Date"]
trace5 = scatter_plot(cnt_srs, 'red') fig = tools.make_subplots(rows=1, cols=1, vertical_spacing=0.08,
subplot_titles=["Total water availability from all four reservoirs - in mcft"])
fig.append_trace(trace5, 1, 1) fig['layout'].update(height=400, width=800, paper_bgcolor='rgb(233,233,233)')
py.iplot(fig, filename='h2o-plots')
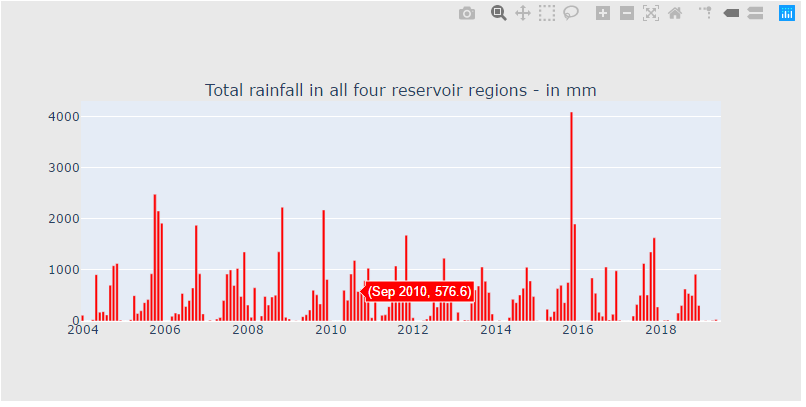
rain_df = pd.read_csv("F:\\kaggleDataSet\\chennai-water\\chennai_reservoir_rainfall.csv")
rain_df["Date"] = pd.to_datetime(rain_df["Date"], format='%d-%m-%Y')
rain_df["total"] = rain_df["POONDI"] + rain_df["CHOLAVARAM"] + rain_df["REDHILLS"] + rain_df["CHEMBARAMBAKKAM"]
rain_df["total"] = rain_df["POONDI"] + rain_df["CHOLAVARAM"] + rain_df["REDHILLS"] + rain_df["CHEMBARAMBAKKAM"]
def bar_plot(cnt_srs, color):
trace = go.Bar(
x=cnt_srs.index[::-1],
y=cnt_srs.values[::-1],
showlegend=False,
marker=dict(
color=color,
))
return trace
rain_df["YearMonth"] = pd.to_datetime(rain_df["Date"].dt.year.astype(str) + rain_df["Date"].dt.month.astype(str), format='%Y%m')
cnt_srs = rain_df.groupby("YearMonth")["total"].sum()
trace5 = bar_plot(cnt_srs, 'red')
fig = tools.make_subplots(rows=1, cols=1, vertical_spacing=0.08,
subplot_titles=["Total rainfall in all four reservoir regions - in mm"])
fig.append_trace(trace5, 1, 1)
fig['layout'].update(height=400, width=800, paper_bgcolor='rgb(233,233,233)')
py.iplot(fig, filename='h2o-plots')
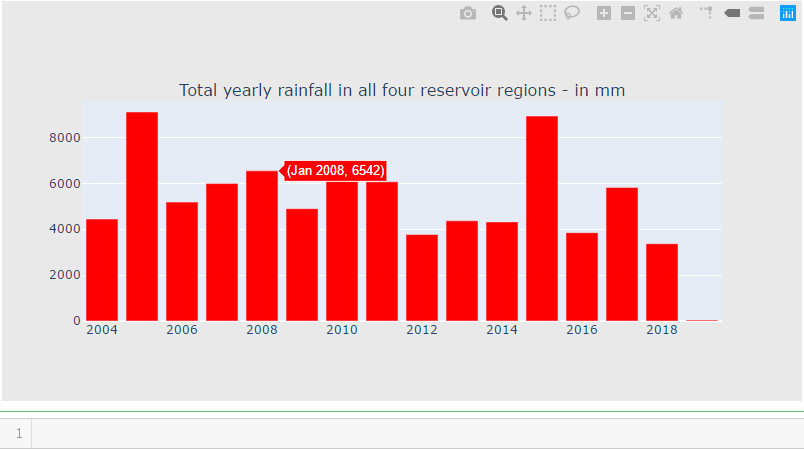
rain_df["Year"] = pd.to_datetime(rain_df["Date"].dt.year.astype(str), format='%Y')
cnt_srs = rain_df.groupby("Year")["total"].sum()
trace5 = bar_plot(cnt_srs, 'red')
fig = tools.make_subplots(rows=1, cols=1, vertical_spacing=0.08,
subplot_titles=["Total yearly rainfall in all four reservoir regions - in mm"])
fig.append_trace(trace5, 1, 1)
fig['layout'].update(height=400, width=800, paper_bgcolor='rgb(233,233,233)')
py.iplot(fig, filename='h2o-plots')
temp_df = df[(df["Date"].dt.month==2) & (df["Date"].dt.day==1)] cnt_srs = temp_df["total"]
cnt_srs.index = temp_df["Date"]
trace5 = bar_plot(cnt_srs, 'red') fig = tools.make_subplots(rows=1, cols=1, vertical_spacing=0.08,
subplot_titles=["Availability of total reservoir water (4 major ones) at the beginning of summer"])
fig.append_trace(trace5, 1, 1) fig['layout'].update(height=400, width=800, paper_bgcolor='rgb(233,233,233)')
py.iplot(fig, filename='h2o-plots')

结论:
2004年的水资源短缺使维拉南湖成为城市供水的新途径。
希望目前的缺水能为这个陷入困境的城市带来更多额外的水源。在过去的15年里,这个城市发展了很多,因此需要额外的水资源来满足需求。
城市需要通过提前估计需求来设计更好的稀缺控制方法。现在,
“只有下雨才能拯救这座城市!”
吴裕雄--天生自然 PYTHON数据分析:钦奈水资源管理分析的更多相关文章
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:葡萄酒分析
# import pandas import pandas as pd # creating a DataFrame pd.DataFrame({'Yes': [50, 31], 'No': [101 ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- 吴裕雄--天生自然 python数据分析:医疗费数据分析
import numpy as np import pandas as pd import os import matplotlib.pyplot as pl import seaborn as sn ...
- 吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results import numpy as np import ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
- 吴裕雄--天生自然 PYTHON数据分析:医疗数据分析
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.rea ...
随机推荐
- @Component, @Repository, @Service,@Controller的区别
@Component, @Service, @Controller, @Repository是spring注解,注解后可以被spring框架所扫描并注入到spring容器来进行管理 @Componen ...
- 第五章——Pytorch中常用的工具
2018年07月07日 17:30:40 __矮油不错哟 阅读数:221 1. 数据处理 数据加载 ImageFolder DataLoader加载数据 sampler:采样模块 1. 数据处理 ...
- 【hdu6613】Squrirrel 树形DP
题意:给一个带权树,求把一条边的权值变成0,再选一个点做根,最大深度最小是多少. \(\sum n \le 10^6\) key:树形DP 题里有边权小于等于200,然而并没有什么用. 首先做出 \( ...
- rclone使用心得
https://rclone.org/ 一边使用一边更新. 0x00 常用rclone命令: 1) 复制:从remote1到remote2 rclone copy -P remote:path rem ...
- dubbo配置文件加载顺序
JVM 启动 -D 参数优先,这样可以使用户在部署和启动时进行参数重写,比如在启动时需改变协议的端口. XML 次之,如果在 XML 中有配置,则 dubbo.properties 中的相应配置项无效 ...
- Monkey安装与配置教程
一.JAVA环境的搭建 安装jdk1.8.0_221,完成环境变量的配置 然后再在系统变量中找到Path,添加%JAVA_HOME%\bin;,确定后,按win+r打开运行,输入cmd 在cmd窗口中 ...
- Monkey通过安装包获取包名
在monkey命令中,包名常作为一个参数.但我们经常知道apk文件,却不知道包名. 如何获取包名呢? 方法一:AAPT 在SDK的build-tools目录下,aapt工具可以查看,创建,更新zip格 ...
- Maven 仓库搜索服务和私服搭建
Maven 仓库搜索服务 使用maven进行日常开发的时候,一个常见问题就是如何寻找需要的依赖,我们可能只知道需要使用类库的项目名称,但是添加maven依赖要求提供确切的maven坐标,这时就可以使用 ...
- 一文带你了解BOM基本知识
1.1. BOM和DOM的区别DOM就是一套操作HTML标签的API(接口/方法/属性) BOM就是一套操作浏览器的API(接口/方法/属性) 1.2. BOM中常见的对象window: 代表整个浏览 ...
- BZOJ3566 [SHOI2014]概率充电器 (树形DP&概率DP)
3566: [SHOI2014]概率充电器 Description 著名的电子产品品牌 SHOI 刚刚发布了引领世界潮流的下一代电子产品——概率充电器:“采用全新纳米级加工技术,实现元件与导线能否通电 ...