吴裕雄--天生自然 PYTHON数据分析:钦奈水资源管理分析
df = pd.read_csv("F:\\kaggleDataSet\\chennai-water\\chennai_reservoir_levels.csv")
df["Date"] = pd.to_datetime(df["Date"], format='%d-%m-%Y')
df.head()

import datetime def scatter_plot(cnt_srs, color):
trace = go.Scatter(
x=cnt_srs.index[::-1],
y=cnt_srs.values[::-1],
showlegend=False,
marker=dict(
color=color,
),
)
return trace cnt_srs = df["POONDI"]
cnt_srs.index = df["Date"]
trace1 = scatter_plot(cnt_srs, 'red') cnt_srs = df["CHOLAVARAM"]
cnt_srs.index = df["Date"]
trace2 = scatter_plot(cnt_srs, 'blue') cnt_srs = df["REDHILLS"]
cnt_srs.index = df["Date"]
trace3 = scatter_plot(cnt_srs, 'green') cnt_srs = df["CHEMBARAMBAKKAM"]
cnt_srs.index = df["Date"]
trace4 = scatter_plot(cnt_srs, 'purple') subtitles = ["Water Availability in Poondi reservoir - in mcft",
"Water Availability in Cholavaram reservoir - in mcft",
"Water Availability in Redhills reservoir - in mcft",
"Water Availability in Chembarambakkam reservoir - in mcft"
]
fig = tools.make_subplots(rows=4, cols=1, vertical_spacing=0.08,
subplot_titles=subtitles)
fig.append_trace(trace1, 1, 1)
fig.append_trace(trace2, 2, 1)
fig.append_trace(trace3, 3, 1)
fig.append_trace(trace4, 4, 1)
fig['layout'].update(height=1200, width=800, paper_bgcolor='rgb(233,233,233)')
py.iplot(fig, filename='h2o-plots')
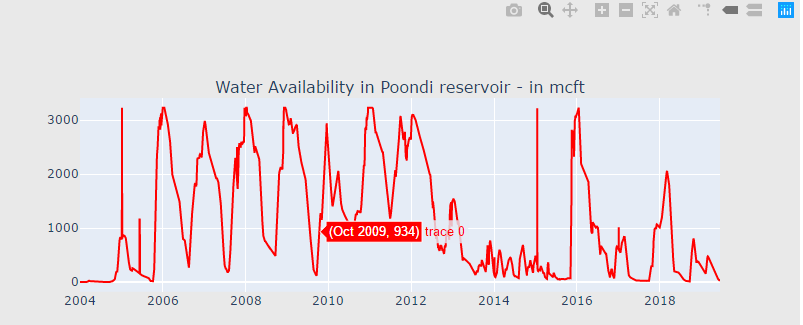
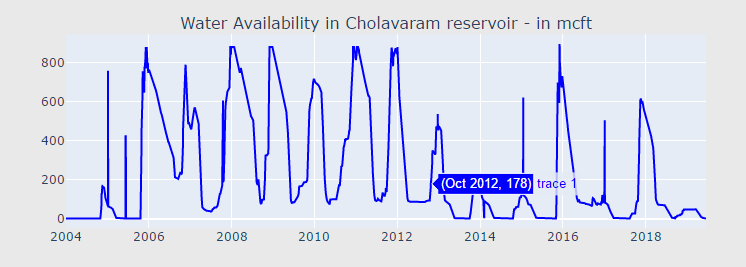

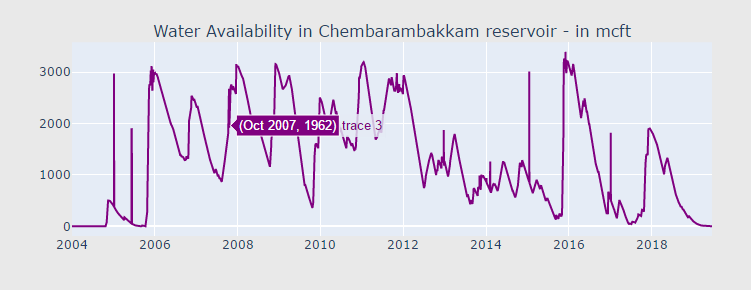
df["total"] = df["POONDI"] + df["CHOLAVARAM"] + df["REDHILLS"] + df["CHEMBARAMBAKKAM"]
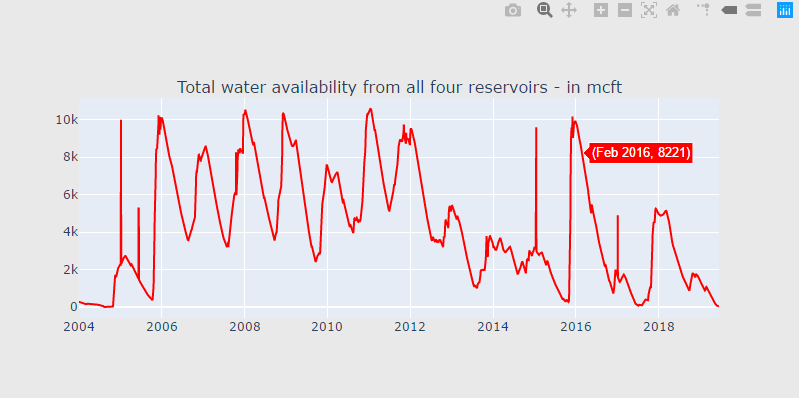
df["total"] = df["POONDI"] + df["CHOLAVARAM"] + df["REDHILLS"] + df["CHEMBARAMBAKKAM"] cnt_srs = df["total"]
cnt_srs.index = df["Date"]
trace5 = scatter_plot(cnt_srs, 'red') fig = tools.make_subplots(rows=1, cols=1, vertical_spacing=0.08,
subplot_titles=["Total water availability from all four reservoirs - in mcft"])
fig.append_trace(trace5, 1, 1) fig['layout'].update(height=400, width=800, paper_bgcolor='rgb(233,233,233)')
py.iplot(fig, filename='h2o-plots')
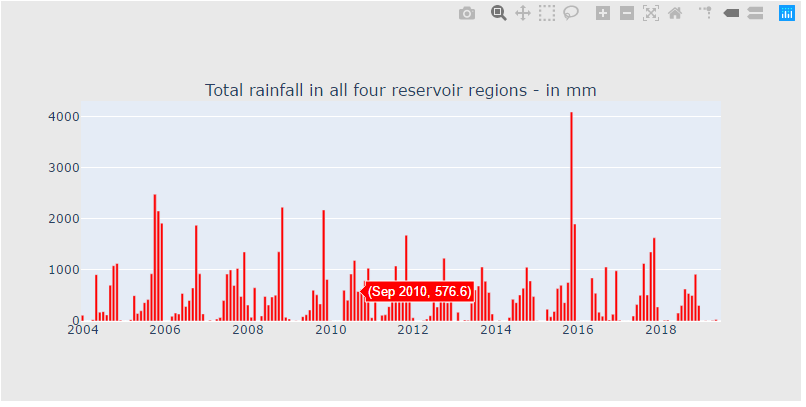
rain_df = pd.read_csv("F:\\kaggleDataSet\\chennai-water\\chennai_reservoir_rainfall.csv")
rain_df["Date"] = pd.to_datetime(rain_df["Date"], format='%d-%m-%Y')
rain_df["total"] = rain_df["POONDI"] + rain_df["CHOLAVARAM"] + rain_df["REDHILLS"] + rain_df["CHEMBARAMBAKKAM"]
rain_df["total"] = rain_df["POONDI"] + rain_df["CHOLAVARAM"] + rain_df["REDHILLS"] + rain_df["CHEMBARAMBAKKAM"]
def bar_plot(cnt_srs, color):
trace = go.Bar(
x=cnt_srs.index[::-1],
y=cnt_srs.values[::-1],
showlegend=False,
marker=dict(
color=color,
))
return trace
rain_df["YearMonth"] = pd.to_datetime(rain_df["Date"].dt.year.astype(str) + rain_df["Date"].dt.month.astype(str), format='%Y%m')
cnt_srs = rain_df.groupby("YearMonth")["total"].sum()
trace5 = bar_plot(cnt_srs, 'red')
fig = tools.make_subplots(rows=1, cols=1, vertical_spacing=0.08,
subplot_titles=["Total rainfall in all four reservoir regions - in mm"])
fig.append_trace(trace5, 1, 1)
fig['layout'].update(height=400, width=800, paper_bgcolor='rgb(233,233,233)')
py.iplot(fig, filename='h2o-plots')
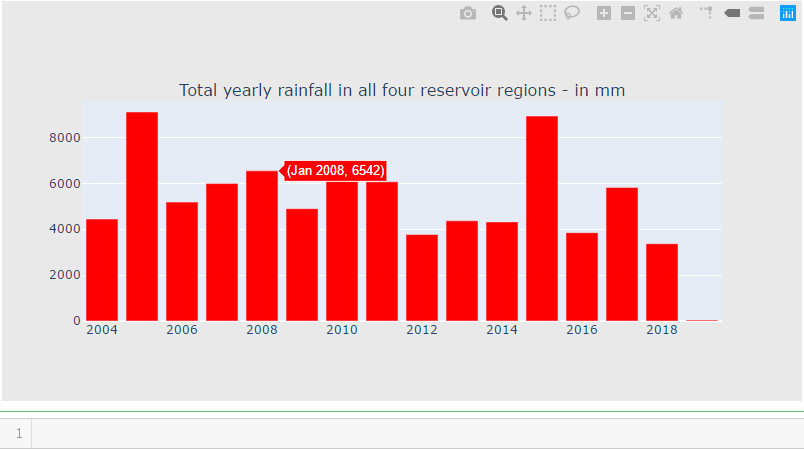
rain_df["Year"] = pd.to_datetime(rain_df["Date"].dt.year.astype(str), format='%Y')
cnt_srs = rain_df.groupby("Year")["total"].sum()
trace5 = bar_plot(cnt_srs, 'red')
fig = tools.make_subplots(rows=1, cols=1, vertical_spacing=0.08,
subplot_titles=["Total yearly rainfall in all four reservoir regions - in mm"])
fig.append_trace(trace5, 1, 1)
fig['layout'].update(height=400, width=800, paper_bgcolor='rgb(233,233,233)')
py.iplot(fig, filename='h2o-plots')
temp_df = df[(df["Date"].dt.month==2) & (df["Date"].dt.day==1)] cnt_srs = temp_df["total"]
cnt_srs.index = temp_df["Date"]
trace5 = bar_plot(cnt_srs, 'red') fig = tools.make_subplots(rows=1, cols=1, vertical_spacing=0.08,
subplot_titles=["Availability of total reservoir water (4 major ones) at the beginning of summer"])
fig.append_trace(trace5, 1, 1) fig['layout'].update(height=400, width=800, paper_bgcolor='rgb(233,233,233)')
py.iplot(fig, filename='h2o-plots')

结论:
2004年的水资源短缺使维拉南湖成为城市供水的新途径。
希望目前的缺水能为这个陷入困境的城市带来更多额外的水源。在过去的15年里,这个城市发展了很多,因此需要额外的水资源来满足需求。
城市需要通过提前估计需求来设计更好的稀缺控制方法。现在,
“只有下雨才能拯救这座城市!”
吴裕雄--天生自然 PYTHON数据分析:钦奈水资源管理分析的更多相关文章
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:葡萄酒分析
# import pandas import pandas as pd # creating a DataFrame pd.DataFrame({'Yes': [50, 31], 'No': [101 ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- 吴裕雄--天生自然 python数据分析:医疗费数据分析
import numpy as np import pandas as pd import os import matplotlib.pyplot as pl import seaborn as sn ...
- 吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results import numpy as np import ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
- 吴裕雄--天生自然 PYTHON数据分析:医疗数据分析
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.rea ...
随机推荐
- python paramiko登陆设备
一,单线程 - shell交互 def chan_recv(chan): data = chan.recv(1024) # 收1024数据 sys.stdout.write(data.decode() ...
- p2p gossip 结构化 非结构化
p2p P2P中文名字叫对等网络,网络中节点地位一致. QQ其实不算P2P,因为QQ利用了中央服务器. Hbase这样的分布式系统,因为有Hmaster节点,也不算是P2P网络: cas ...
- PowerShell-Selenium技术实时调试和操作Chrome浏览器
只需要4行代码: $AnyWindow=$Chrome.WindowHandles.Item() $Chrome=$Chrome.SwitchTo().Window($AnyWindow) Write ...
- linux上systemctl使用
转载:https://www.cnblogs.com/zdz8207/p/linux-systemctl.html Linux服务器,服务管理--systemctl命令详解,设置开机自启动 syete ...
- TPO2-1Desert Formation
The extreme seriousness of desertification results from the vast areas of land and the tremendous nu ...
- CLOUD信用管理设置
1.参数设置(管理员账户) 2.客户管理-信用管理设置 3.信用检查规则设置 4.信用档案设置 5.涉及集团公司,母公司与子公司的设置 6.信用档案-对象类型可为客户及集团客户 7.信用特批权限设置 ...
- Learn Git Lesson06 - 分离头指针
============== 知识点 分离头指针 HEAD 含义 git diff 分离头指针 (Detached HEAD) 有时候想尝试性修改某些内容(实验),也许并不会真的提交到分支,这时候可以 ...
- PostgreSQL中实现更新默认值(二)
今天我们用表继承+触发器的方案,来实现表中的更新默认值.这也许是PostgreSQL里最佳的解决方案. 一. 创建一张表,作为父表 create table basic_update( t_updat ...
- spring boot学习4 多环境配置
说明: 在企业中,一个项目一般都有测试环境(test) .开发环境(dev).生产环境(pro)等等.在每个环境中,配置信息会不一样的.比如数据库.静态资源文件位置等都会不一样的. 那么使用sprin ...
- Excel-DNA开发包:ExcelDna-0.34.6.zip下载
Excel-DNA可以用VB.Net或C#开发Excel自定义函数.制作.xll格式的加载宏. 点此下载 ExcelDna-0.34.6.zip