吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) # Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
df=pd.read_csv('F:\\kaggleDataSet\\Key_indicator_districtwise\\Key_indicator_districtwise.csv')
df.head()
x=df['AA_Sample_Units_Total']
y=df['AA_Sample_Units_Rural']
z=df['AA_Population_Urban']
import matplotlib.pyplot as plt
import seaborn as sns
plt.title('State_District_Name vs AA_Sample_Units_Total ')
plt.xlabel('State_District_Name')
plt.ylabel('AA_Sample_Units_Total')
plt.scatter(x,y)
plt.hist(x)
plt.title('AA_Sample_Units_Total vs Frequency')
plt.xlabel('AA_Sample_Units_Total')
plt.ylabel('Frequency')
plt.hist(y)
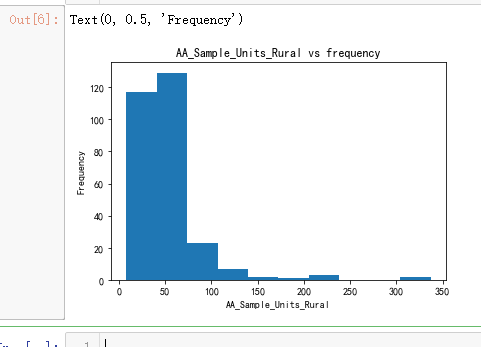
plt.title('AA_Sample_Units_Rural vs frequency')
plt.xlabel('AA_Sample_Units_Rural')
plt.ylabel('Frequency')
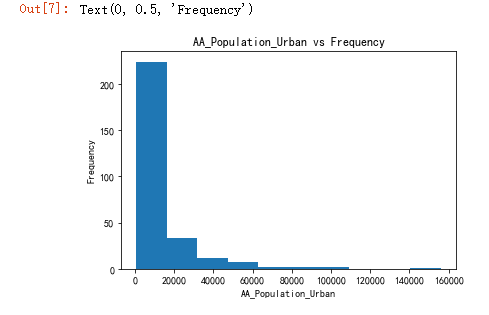
plt.hist(z)
plt.title('AA_Population_Urban vs Frequency')
plt.xlabel('AA_Population_Urban')
plt.ylabel('Frequency')
q=df['AA_Ever_Married_Women_Aged_15_49_Years_Total']
q
w=q.sort_values()
w

plt.boxplot(w)

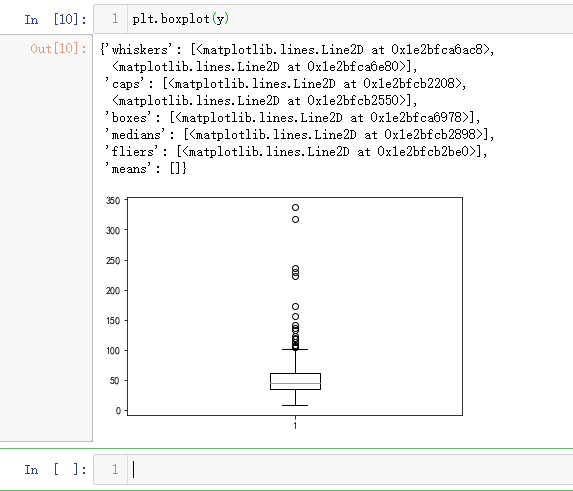
plt.boxplot(y)
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model, metrics # load the boston dataset
boston = datasets.load_boston(return_X_y=False) # defining feature matrix(X) and response vector(y)
X = boston.data
y = boston.target # splitting X and y into training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4,
random_state=1) # create linear regression object
reg = linear_model.LinearRegression() # train the model using the training sets
reg.fit(X_train, y_train) # regression coefficients
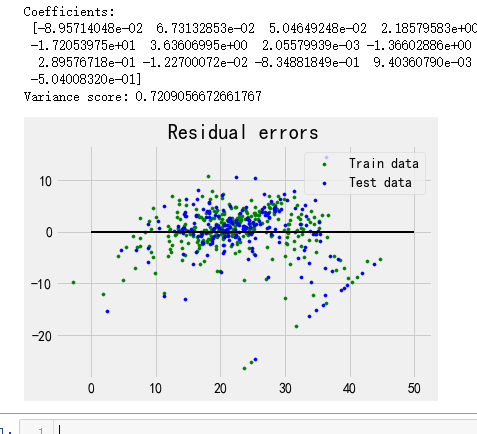
print('Coefficients: \n', reg.coef_) # variance score: 1 means perfect prediction
print('Variance score: {}'.format(reg.score(X_test, y_test))) # plot for residual error ## setting plot style
plt.style.use('fivethirtyeight') ## plotting residual errors in training data
plt.scatter(reg.predict(X_train), reg.predict(X_train) - y_train,
color = "green", s = 10, label = 'Train data') ## plotting residual errors in test data
plt.scatter(reg.predict(X_test), reg.predict(X_test) - y_test,
color = "blue", s = 10, label = 'Test data') ## plotting line for zero residual error
plt.hlines(y = 0, xmin = 0, xmax = 50, linewidth = 2) ## plotting legend
plt.legend(loc = 'upper right') ## plot title
plt.title("Residual errors") ## function to show plot
plt.show()
吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)的更多相关文章
- 吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results import numpy as np import ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:葡萄酒分析
# import pandas import pandas as pd # creating a DataFrame pd.DataFrame({'Yes': [50, 31], 'No': [101 ...
- 吴裕雄--天生自然 python数据分析:医疗费数据分析
import numpy as np import pandas as pd import os import matplotlib.pyplot as pl import seaborn as sn ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
- 吴裕雄--天生自然 PYTHON数据分析:钦奈水资源管理分析
df = pd.read_csv("F:\\kaggleDataSet\\chennai-water\\chennai_reservoir_levels.csv") df[&quo ...
- 吴裕雄--天生自然 PYTHON数据分析:医疗数据分析
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.rea ...
随机推荐
- nginx常用模块(一)
1.Nginx目录索引 1.1Nginx默认是不允许列出整个目录浏览下载.Syntax: autoindex on | off;Default: autoindex off;Context: http ...
- ZJNU 1125 - A == B ?——中级
处理后再判断即可,处理过程注意考虑全面. /* Written By. StelaYuri */ #include<iostream> #include<string> usi ...
- Bless All
# php code $i = 2333 $myJXOI = JXOI() while($i == 2333){ ++myJXOI.score , ++myJXOI.rp , --myJXOI.常数 ...
- [HNOI2019]白兔之舞(矩阵快速幂+单位根反演)
非常抱歉,这篇文章鸽了.真的没时间写了. #include<bits/stdc++.h> using namespace std; typedef long long ll; #defin ...
- matlab设置mex失败
更新 使用matlab2017b时,又报错, >> mex -setup 警告: Xcode is installed, but its license has not been acce ...
- tomcat高并发配置
最近在项目中负责Tomcat高并发优化方案写一写新得. 优化1)tomcat默认的并发是75,可以启用线程池根据生产环境硬件设定线程池大小. <Executor name="tomca ...
- matplotlib学习——设置线条颜色及形状
在图形表示中,不同的画布或画布中不同的函数,我们常常要用不同的形状或颜色来区分开,这里小编向大家介绍这些参数的表示方法: 一.控制颜色 b--blue c--cyan(青色) ...
- 提高线程数,解决redis超时问题
根据压测结果做出的修改历史: 第一步:只针对maxWorkerThreads.maxIoThreads和minWorkerThreads做了修改<processModel autoConfig= ...
- The Five-Number Summary|Boxplots
3.3 The Five-Number Summary; Boxplots the deciles divide a data set into tenths (10 equal parts), th ...
- Python练习四-浅拷贝&深拷贝
一.数字.字符串不论是浅拷贝.深拷贝都是指向一个地址. a = 1 b = "abc" print (id(a)) print (id(b)) a1 = a b1 = b prin ...