吴裕雄--天生自然 python数据分析:葡萄酒分析
# import pandas
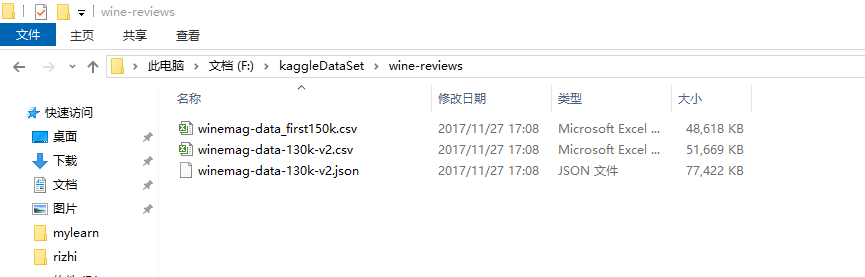
import pandas as pd # creating a DataFrame
pd.DataFrame({'Yes': [50, 31], 'No': [101, 2]})
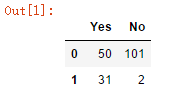
# another example of creating a dataframe
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland']})
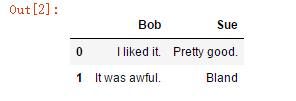
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index = ['Product A', 'Product B'])

# creating a pandas series
pd.Series([1, 2, 3, 4, 5])

# we can think of a Series as a column of a DataFrame.
# we can assign index values to Series in same way as pandas DataFrame
pd.Series([10, 20, 30], index=['2015 sales', '2016 sales', '2017 sales'], name='Product A')

# reading a csv file and storing it in a variable
wine_reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv")
# we can use the 'shape' attribute to check size of dataset
wine_reviews.shape
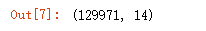
# To show first five rows of data, use 'head()' method
wine_reviews.head()
wine_reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv", index_col=0)
wine_reviews.head()
wine_reviews.head().to_csv("F:\\wine_reviews.csv")
import pandas as pd
reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv", index_col=0)
pd.set_option("display.max_rows", 5)
reviews
# access 'country' property (or column) of 'reviews'
reviews.country

# Another way to do above operation
# when a column name contains space, we have to use this method
reviews['country']
# To access first row of country column
reviews['country'][0]

# returns first row
reviews.iloc[0]

# returns first column (country) (all rows due to ':')
reviews.iloc[:, 0]
# retruns first 3 rows of first column
reviews.iloc[:3, 0]

# we can pass a list of indices of rows/columns to select
reviews.iloc[[0, 1, 2, 3], 0]

# We can also pass negative numbers as we do in Python
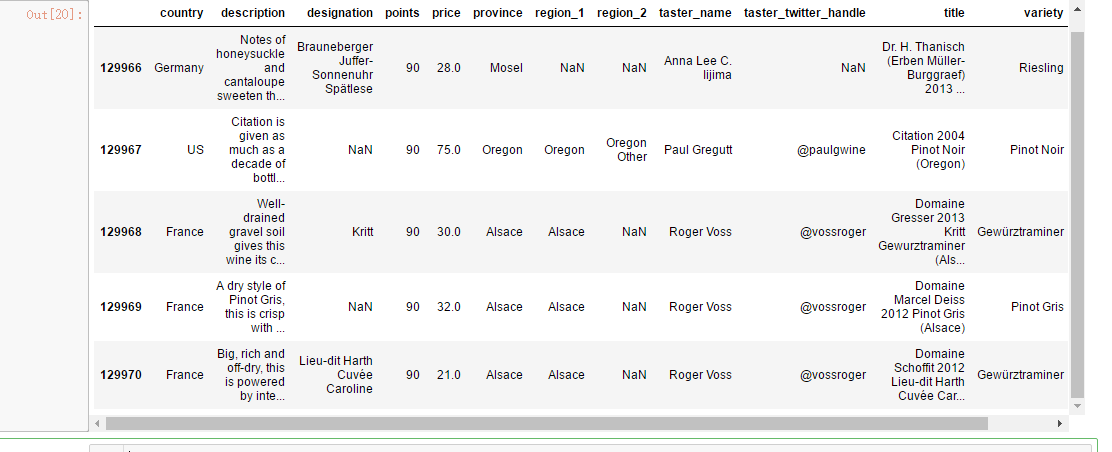
reviews.iloc[-5:]
# To select first entry in country column
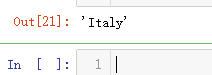
reviews.loc[0, 'country']
# select columns by name using 'loc'
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
# 'set_index' to the 'title' field
reviews.set_index('title')

# 1. Find out whether wine is produced in Italy
reviews.country == 'Italy'

# 2. Now select all wines produced in Italy
reviews.loc[reviews.country == 'Italy'] #reviews[reviews.country == 'Italy']
# Add one more condition for points to find better than average wines produced in Italy
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)] # use | for 'OR' condition
reviews.loc[reviews.country.isin(['Italy', 'France'])]
reviews.loc[reviews.price.notnull()]
reviews['critic'] = 'everyone'
reviews.critic

# using iterable for assigning
reviews['index_backwards'] = range(len(reviews), 0, -1)
reviews['index_backwards']

吴裕雄--天生自然 python数据分析:葡萄酒分析的更多相关文章
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results import numpy as np import ...
- 吴裕雄--天生自然 PYTHON数据分析:钦奈水资源管理分析
df = pd.read_csv("F:\\kaggleDataSet\\chennai-water\\chennai_reservoir_levels.csv") df[&quo ...
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- 吴裕雄--天生自然 python数据分析:医疗费数据分析
import numpy as np import pandas as pd import os import matplotlib.pyplot as pl import seaborn as sn ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
- 吴裕雄--天生自然 PYTHON数据分析:医疗数据分析
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.rea ...
随机推荐
- Halcon中将16位的图像转化为8位的图像
Halcon中Image有多种像素表示方式,这方面网上找到的资料比较少,有一张大恒图像培训的文档中提到过,感觉描述比较准确: 里面有四种类型比较类似:uint2.int1.int2.int4. 区分起 ...
- linux安装java步骤
本文转发自博客园-Q鱼丸粗面Q.博客园-郁冬的文章,内容略有改动 本文已收录至博客专栏linux安装各种软件及配置环境教程中 方式一:yum方式下载安装 1.查找java相关的列表 yum -y li ...
- 微信小程序java8 java7 java6 encryptedData 解密 异常处理
使用java8 java7 java6 解密微信小程序encryptedData可以回遇到一些错误 1.java.security.NoSuchAlgorithmException: Cannot ...
- 脚本kafka-configs.sh用法解析
引用博客来自李志涛:https://www.cnblogs.com/lizherui/p/12275193.html 前言介绍 网络上针对脚本kafka-configs.sh用法,也有一些各种文章,但 ...
- 填平新版本Xcode安装插件不成功的坑
一般情况下,安装xcode不成功现象基本上都出现在更新xcode或者重装之后出现的情况,下面原理性德东西,我就不赘述了,度娘上很容易看到,通过这段只是希望大家花费尽量少得时间将xcode插件安装成功. ...
- Kaggle——NFL Big Data Bowl
neural networks + feature engineering for the win 导入需要的库 import numpy as np import pandas as pd impo ...
- beta函数分布图
set.seed(1) x<-seq(-5,5,length.out=10000) a = c(.5,0.6, 0.7, 0.8, 0.9) b = c(.5, 1, 1, 2, 5) colo ...
- 吴裕雄--天生自然 PYTHON3开发学习:条件控制
if condition_1: statement_block_1 elif condition_2: statement_block_2 else: statement_block_3 var1 = ...
- python+selenium自动化--参数化(paramunittest)
unnittest的参数化模块-paramunittest paramunittest是unittest实现参数化的一个专门的模块,可以传入多组参数,自动生成多个用例 两种用法 import unit ...
- BZOJ2733 [HNOI2012]永无乡(并查集+线段树合并)
题目大意: 在$n$个带权点上维护两个操作: 1)在点$u,v$间连一条边: 2)询问点$u$所在联通块中权值第$k$小的点的编号,若该联通块中的点的数目小于$k$,则输出$-1$: 传送门 上周的模 ...